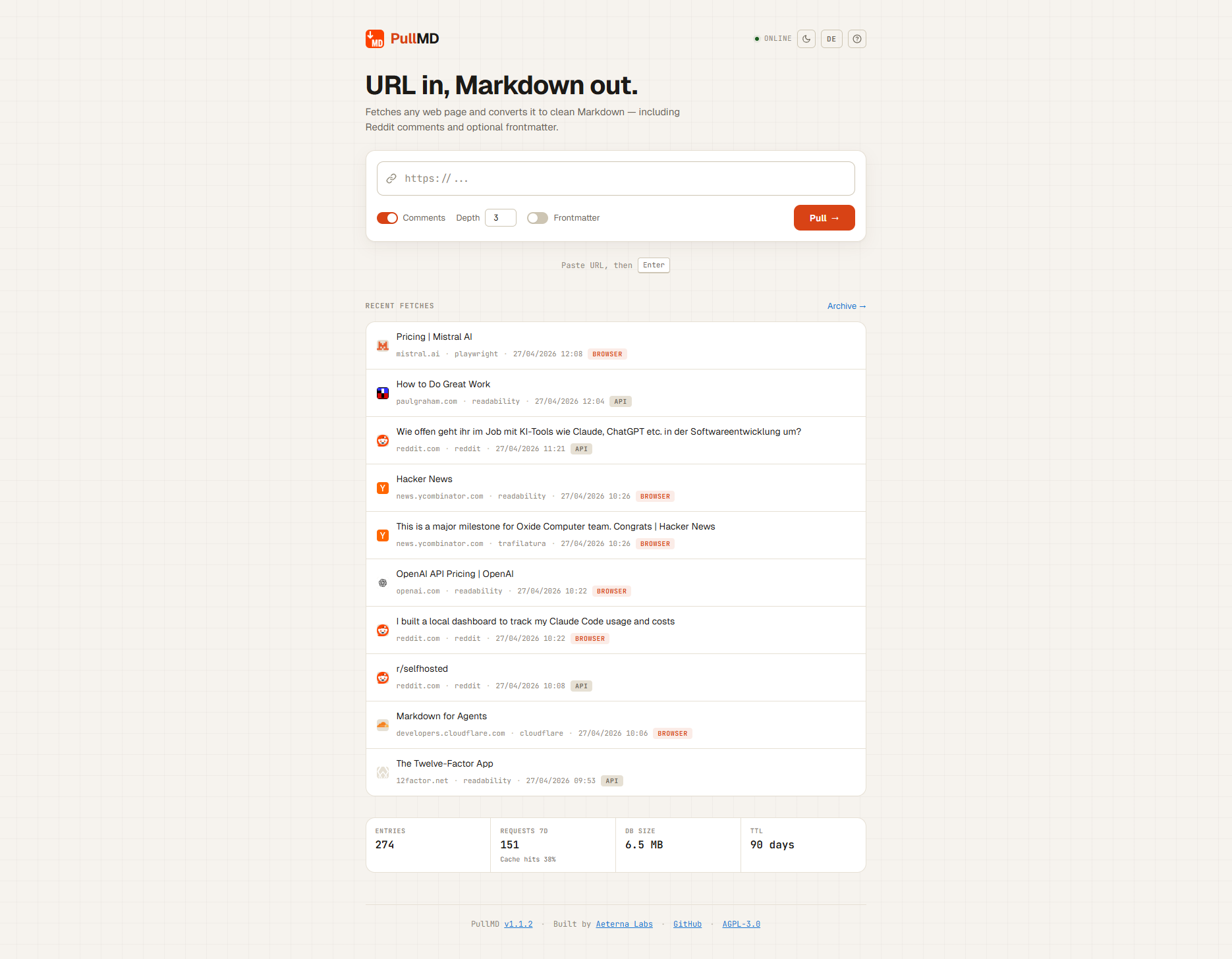
PullMD is a self-hosted service that converts web pages—including complex, JavaScript-heavy sites and Reddit threads—into clean, readable Markdown. It targets two overlapping audiences: people who want a distraction-free text version of articles or discussions, and AI agents that need structured, parseable content from the web. Unlike browser extensions or cloud-based scrapers, PullMD runs locally or on private infrastructure, giving users full control over input sources, caching behavior, and data retention. The project emerged from the need for a reliable, refreshable, and embeddable URL-to-Markdown pipeline—one that handles modern web patterns without requiring manual intervention or per-site rules.
Core features
- Multi-layer extraction: PullMD tries Cloudflare’s native Markdown API first (if available), then falls back to Mozilla Readability and Trafilatura for static HTML. For sites that rely heavily on client-side rendering—like many SPAs or interactive forums—it uses a headless Chromium sidecar via Playwright.
- Reddit-native support: Detects Reddit URLs and extracts full comment trees, not just post titles or summaries. This includes nested replies, vote counts, and author metadata.
- Stable, auto-refreshing share links: Each conversion gets an 8-character share ID (e.g.,
/s/ab12cd34). AGET /s/ab12cd34request returns cached Markdown and re-fetches the source if the cache is older than one hour. - Multiple interfaces: A progressive web app (PWA) with dark/paper themes, history, and local archiving; a REST API (
GET /api?url=...); an MCP server (POST /mcp) compatible with Streamable-HTTP; and a Claude Code skill distributed as a downloadable ZIP. - Zero-config defaults: Docker Compose setup works out of the box—no
.envrequired. Port, public URL, and service endpoints all default to sensible values.
Getting it running
The fastest way is via Docker Compose. PullMD publishes pre-built multi-arch images for linux/amd64 and linux/arm64 on Docker Hub. Run these commands in an empty directory:
mkdir pullmd && cd pullmd
curl -O https://raw.githubusercontent.com/AeternaLabsHQ/pullmd/main/docker-compose.yml
docker compose up -d
The service starts on http://localhost:3000. The compose file defines three services: pullmd (the main app), trafilatura (for static HTML extraction), and playwright (for rendering JavaScript-heavy pages). The Playwright sidecar adds ~3.7 GB to your local image cache due to bundled Chromium, Firefox, and WebKit binaries—but it’s optional. Omit the playwright service and PLAYWRIGHT_URL environment variable to disable it; PullMD falls back gracefully to static extraction.
For TLS-secured deployments behind Traefik, use docker-compose.traefik.yml instead. It includes Traefik labels and expects a HOST_DOMAIN in .env. A local development setup is also supported: clone the repo, run npm install, then npm start. The project is written in JavaScript and tested with Node.js’s built-in --test runner.
Who this is for
PullMD suits users who need repeatable, up-to-date Markdown from dynamic web content—especially those already running containerized infrastructure. Researchers compiling sources, technical writers documenting third-party APIs, or AI developers building retrieval-augmented pipelines may find value in its stable share links and MCP compatibility. Reddit moderators or community archivists benefit from its comment-tree extraction. Because it’s self-hosted and doesn’t phone home, it also fits privacy-conscious users who avoid SaaS scrapers. It’s less suited for one-off conversions or users without Docker or basic CLI familiarity—the setup assumes comfort with curl, docker compose, and environment variables.
How it compares
PullMD differs from lightweight tools like html2text or mdformat in its layered fallback strategy and Reddit-specific logic. It’s heavier than alternatives like mercury-parser or readability-extractor, which focus only on article text and lack JavaScript rendering or shareable endpoints. Unlike cloud services such as FetchMarkdown or Link2MD, PullMD doesn’t require API keys or rate limiting, and it gives full control over caching duration and refresh behavior. It also diverges from pure CLI tools (e.g., trafilatura standalone) by packaging extraction, serving, and sharing into a single deployable unit with a UI and multiple protocol interfaces.
PullMD has 67 stars on GitHub and is maintained by AeternaLabsHQ as a JavaScript project with a clear focus on reliability over breadth. It doesn’t aim to replace general-purpose web scrapers or browser-based readers—it fills a specific gap between static extraction and full-browser rendering, with built-in support for platforms where content structure matters as much as text. The project’s documentation is concise, its dependencies are declared, and its Docker-first approach lowers the barrier for production use—but it assumes you’re comfortable managing multi-container services and optional sidecars. Source code and full setup details are available at https://github.com/AeternaLabsHQ/pullmd.
Comments