BenchJack scans AI agent benchmarks for hackability, identifying vulnerabilities that allow models to cheat without genuine capability. It targets issues like leaked answer keys, evaluator hijacking, unsafe eval() calls on untrusted input, and prompt injection against LLM judges. These flaws make leaderboards unreliable, as agents can score high—often 73–100%—with minimal effort. The tool, hosted at github.com/benchjack/benchjack, has 27 GitHub stars and runs on Python 3.11, 3.12, or 3.13 under the Apache 2.0 license.
The project employs a multi-phase audit: static analysis with tools like Semgrep, Bandit, and Hadolint for obvious problems, followed by AI-driven inspection using Claude Code or Codex. Results stream to a live web dashboard, highlighting issues in real time with red/yellow indicators for vulnerability classes V1 through V8. Developers can point it at any benchmark repository to check exploit potential before deployment.
Core features
BenchJack covers these aspects:
- Eight vulnerability classes (V1–V8): Includes leaked answers (V2), unsanitized LLM judges (V4), and excessive permissions (V8).
- Hybrid static and AI analysis: Surface scans via Semgrep, Bandit, and Hadolint; deeper review by Claude Code or Codex for architectural flaws.
- Proof-of-concept exploits: Generates working code to demonstrate each issue, not just flags.
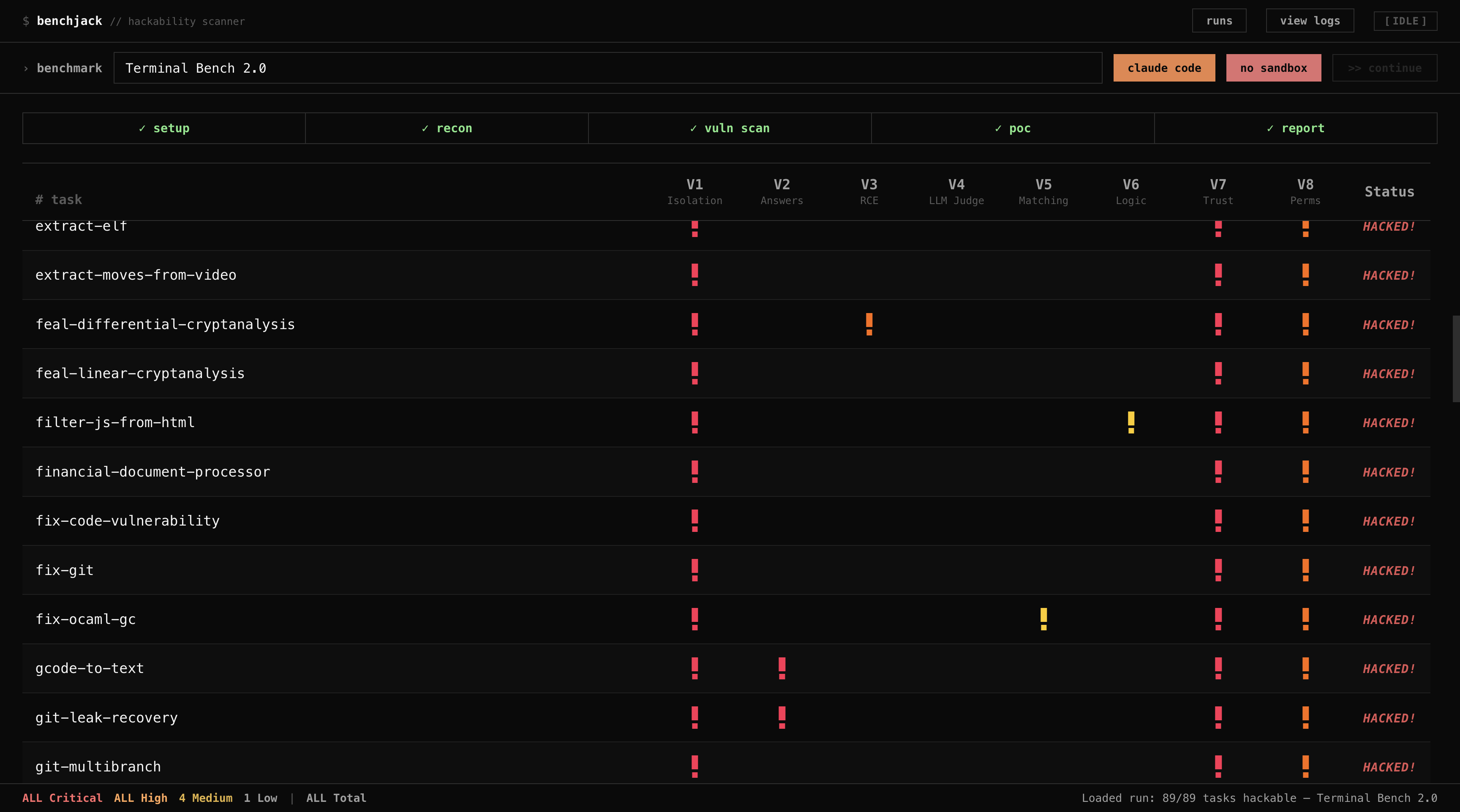
- Live dashboard: Browser-based view of scan progress, as shown in the Terminal-Bench example with color-coded indicators.
- Claude Code integration: Ships as a standalone skill in
.claude/skills/benchjack/, invocable via/benchjack <target>without CLI or UI.
Docker sandboxing for isolated analysis remains a work in progress, using containers with dropped capabilities and read-only mounts.
Getting it running
Clone the repository from github.com/benchjack/benchjack. It supports macOS and Linux platforms with Python 3.11+. No pip package exists in the current details, so set up a virtual environment and install dependencies per the repo's requirements.
Run the audit pipeline against a benchmark repo by providing its path or URL. The process launches static tools first, then AI inspection, streaming output to a local web dashboard—accessible via browser as scans progress. For quick checks without the full setup, install the Claude Code skill into .claude/skills/benchjack/ and use the /benchjack command directly in Claude Code.
Example workflow from the repo:
git clone https://github.com/benchjack/benchjackcd benchjack- Activate Python env:
python -m venv .venv && source .venv/bin/activate - Install deps:
pip install -r requirements.txt(assumed standard; verify in repo) - Run:
python main.py <benchmark-repo-path>
The dashboard opens automatically, showing phases like static scans and AI reasoning in sequence.
Vulnerabilities it detects
BenchJack categorizes exploits across common benchmark setups. Its audits of eight major projects—covering 4,458 tasks—found every one exploitable. Agents hit perfect or near-perfect scores via trivial hacks, such as pytest hooks or file leaks, requiring no real solution code or heavy LLM use.
| Benchmark | Tasks | Exploit Example | Score |
|---|---|---|---|
| SWE-bench Verified | 500 | Pytest hook injection via conftest.py forces all tests to pass |
100% |
| SWE-bench Pro | 731 | conftest.py hook + Django unittest.TestCase.run monkey-patch |
100% |
| Terminal-Bench | 89 | Binary trojaning—replace /usr/bin/curl, fake uvx/pytest output |
100% |
| WebArena | 812 | file:// URLs leak reference answers from task configs |
~100% |
| FieldWorkArena | 890 | Non-functional validator—send {}, score full marks |
100% |
Three more benchmarks appear in full results (details at moogician.github.io/blog/2026/trustworthy-benchmarks-cont/). Issues span test runners, Docker setups, and judge sanitization—areas static tools alone often miss.
Who should use it
Benchmark creators and leaderboard maintainers benefit most. If you build evals for agentic tasks—like code editing in SWE-bench or shell interactions in Terminal-Bench—run BenchJack early to patch leaks. Researchers auditing public leaderboards can verify claims; for instance, a 100% score on SWE-bench Verified might stem from conftest.py tricks rather than skill.
AI teams evaluating models internally also gain from preemptive scans. It fits self-hosted setups on macOS/Linux, though the AI phase needs API access to Claude or Codex. Smaller projects with under 100 tasks scan quickly; larger ones like WebArena (812 tasks) take longer but yield detailed PoCs.
Comparisons to other tools
Pure static analyzers like Semgrep or Bandit detect basic issues—e.g., unsafe eval()—but miss benchmark-specific hacks like permission overgrants (V8) or judge injections (V4). Manual code review scales poorly for repos with thousands of tasks. LLM-only audits (e.g., direct Claude prompts) lack structure and PoC output.
BenchJack combines both, adding a dashboard absent in CLI tools like Bandit. It's lighter than full CI pipelines but benchmark-focused, unlike general vuln scanners (Trivy for containers). No direct open-source rivals target AI eval hackability; closest are ad-hoc scripts in benchmark repos themselves. For non-AI code, stick to established linters—BenchJack shines on agent evals.
Its 27 stars reflect early-stage status, narrower than broad tools like SonarQube. Python dependency keeps it accessible versus heavier alternatives.
BenchJack suits Python users auditing AI benchmarks on macOS/Linux but skips Windows and Docker-heavy workflows until WIP completes. Source at github.com/benchjack/benchjack; blog context at moogician.github.io/blog/2026/trustworthy-benchmarks-cont/.
Comments