Two AIs review. A third attacks. You get the truth.
Before/After · Why Different · Quick Start · Pipeline · Why Not X · TrustEngine · 中文
Before / After
Before: Single-AI Review
┌─────────────────────────────────────────────────────┐
│ You ask an AI to write a login handler. │
│ It comes back confident: │
│ │
│ def login(username, password): │
│ query = "SELECT * FROM users " │
│ query += "WHERE name='" + username + "'" │
│ query += " AND password='" + hash(password) │
│ return db.execute(query) │
│ │
│ A single AI reviewer says: "Looks fine." │
│ │
│ ❌ SQL injection in line 3 — missed. │
│ ❌ hash() is not cryptographic — missed. │
│ ❌ No rate limiting — missed. │
│ │
│ One model. One perspective. Three blind spots. │
└─────────────────────────���───────────────────────────┘
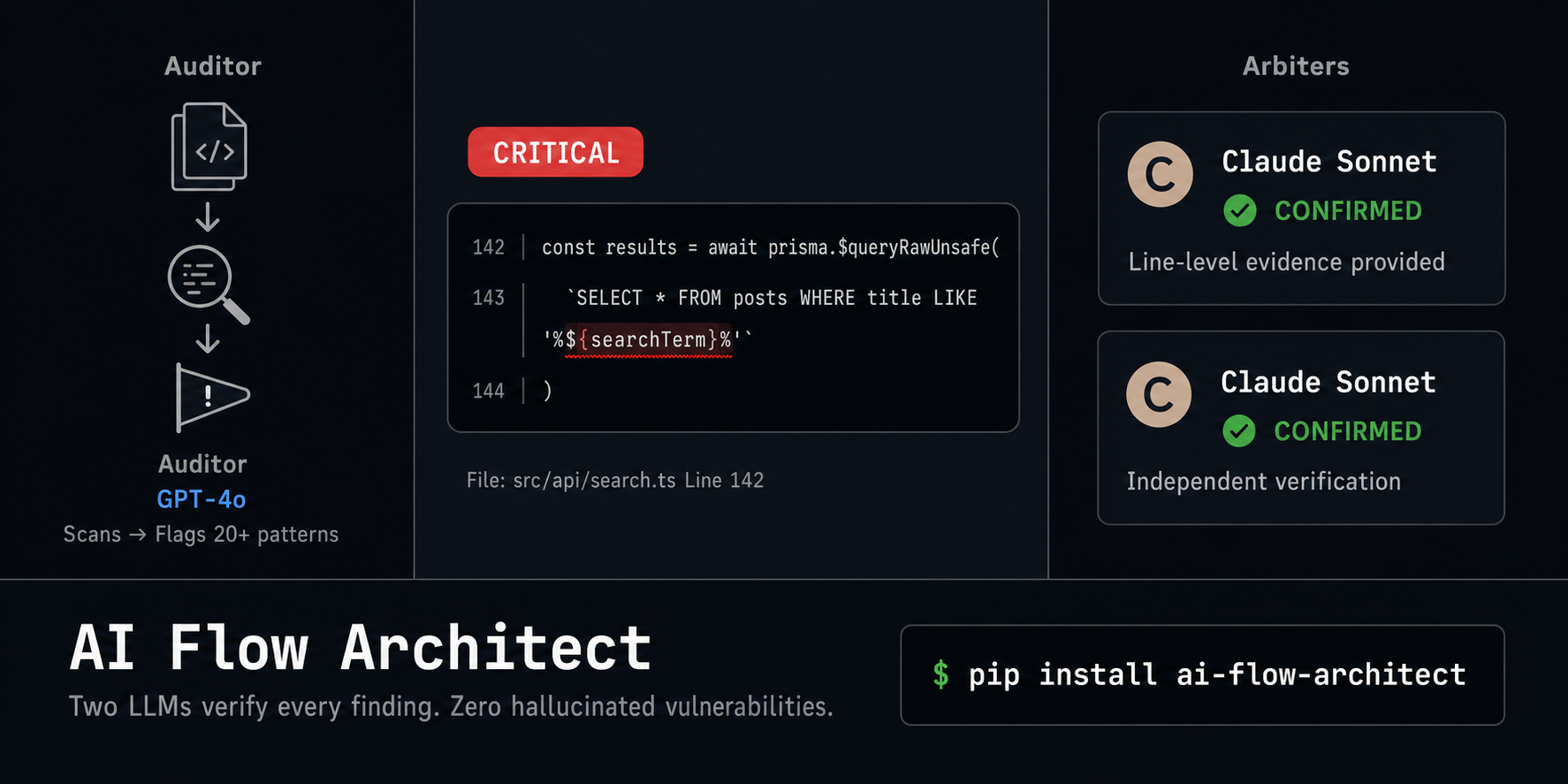
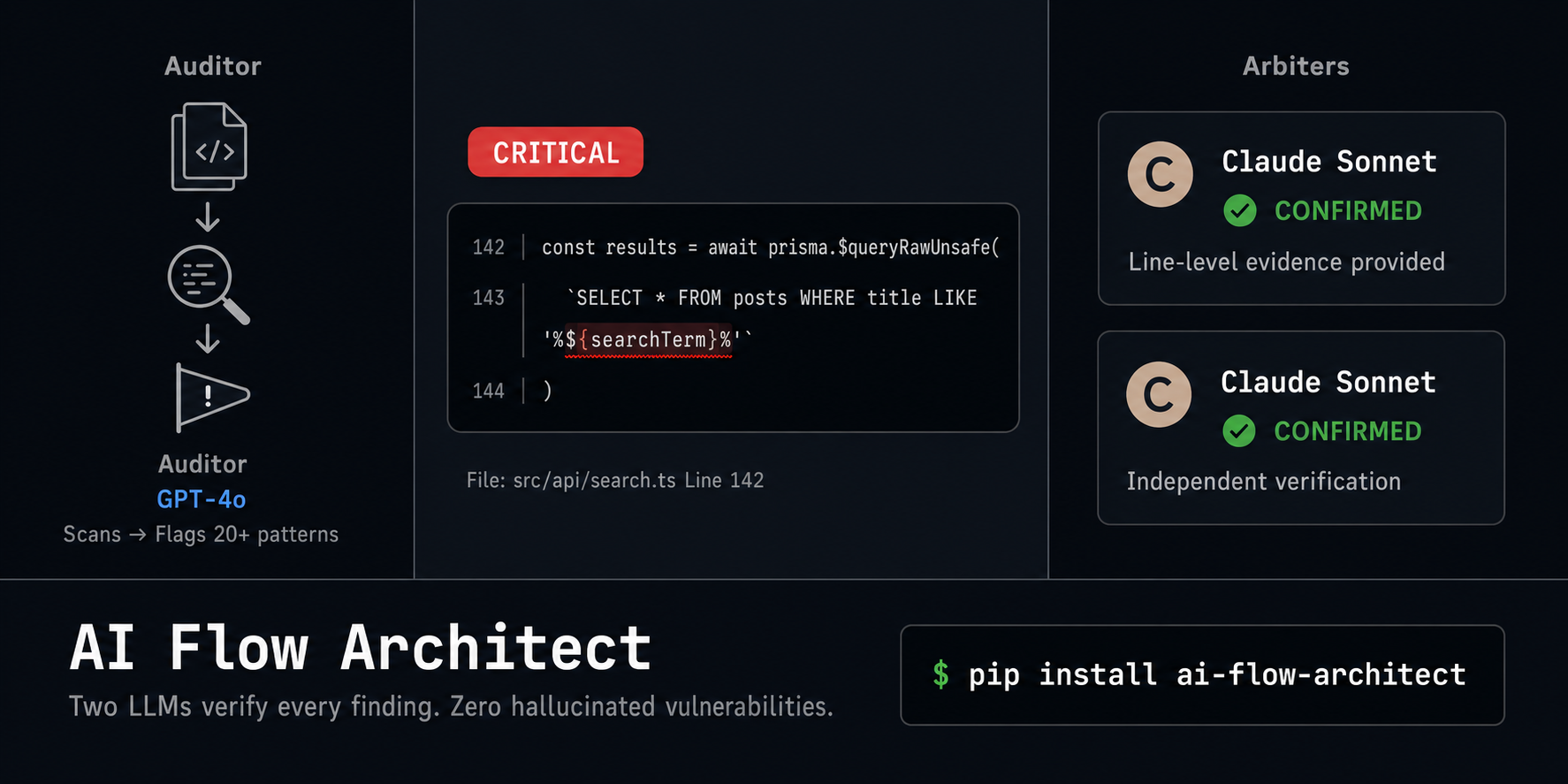
After: ai-flow-architect Adversarial Audit
┌──────────────────────────────────────────────────────────┐
│ Brain One (GPT-4o): Primary audit — flags SQL injection, │
│ unsafe hash, missing rate limit. │
│ │
│ Opponent Brain (Claude 3.5 Sonnet): Attacks the same │
│ code from 5 adversarial angles — confirms Brain One's │
│ findings, adds: race condition in session renewal. │
│ │
│ Cross-Verification: Where they agree → confirmed finding.│
│ Where they disagree → flagged UNCERTAIN, not hidden. │
│ │
│ TrustReport — REJECT (confidence 32/100) │
│ │
│ > [CRITICAL] SQL Injection — username concatenated │
│ directly into query string at line 3 │
│ "Attacker input ' OR 1=1 -- bypasses auth entirely" │
│ │
��� > [HIGH] Unsafe Hash — hash() is not a cryptographic │
│ function. Use bcrypt or argon2. │
│ │
│ > [MEDIUM] Missing Rate Limit — brute-forceable in │
│ under 10 minutes. Add exponential backoff. │
│ │
│ > [!] UNCERTAIN: Race condition in session renewal — │
│ arbiters disagree. Manual review recommended. │
│ │
│ Evidence chain: a1b2c3... (SHA-256, verifiable) │
│ │
│ ✅ Multi-model consensus on critical findings │
│ ✅ Opponent caught what Brain One missed │
│ ✅ Disagreement surfaced, not suppressed │
└──────────────────────────────────────────────────────────┘
Try the interactive Playground — see real audits of real AI outputs. No installation. No API key.
What Makes This Different
Multi-Model Arbitration. Not a vote. Brain One audits first. Then the Opponent Brain challenges the same output from adversarial angles. Findings that survive both models are confirmed. Disagreements are flagged as UNCERTAIN — not swept under the rug.
Opponent Brain. A dedicated third perspective designed to find flaws. It attacks from five adversarial stances (attacker, edge-case hunter, assumption breaker, spec lawyer, logic checker). Unlike a second-pass review, it actively tries to break the output.
TrustEngine with Cryptographic Evidence. Every finding is hashed with SHA-256 and timestamped. You get a verifiable evidence chain — proof of what was found and when. Share the report. The hash proves it hasn't been tampered with.
Quick Start
pip install ai-flow-architect[html]
Set one API key — or two for cross-provider arbitration (recommended):
export OPENAI_API_KEY="sk-..." # Required
export ANTHROPIC_API_KEY="sk-ant-..." # Optional, for stronger audits
Audit anything in one command:
ai-flow audit login.py -r "Check for SQL injection, auth bypass, and rate limiting"
# Export as a shareable HTML report
ai-flow audit login.py -r "Security audit" --html -o report.html
# Pipe from other tools
cat generated_code.py | ai-flow audit -r "Validate correctness"
# Or use the Python SDK — 3 lines
from ai_flow_architect import TrustEngine
engine = TrustEngine()
report = engine.audit(
requirement="Secure user authentication with rate limiting",
ai_output=ai_generated_code,
)
print(report.summary()) # "REJECT (32/100): 3 findings, 2 uncertain"
How It Works
Input Code
│
▼
┌─────────────────────┐
│ Brain One Audit │ Primary review. Identifies issues across
│ (GPT-4o) │ security, correctness, and logic dimensions.
└─────────┬───────────┘
│ findings
▼
┌─────────────────────┐
│ Opponent Challenge │ 5 adversarial perspectives attack the same
│ (Claude 3.5 Sonnet) │ output. Confirms or disputes each finding.
└─────────┬───────────┘
│ confirmed / disputed
▼
┌─────────────────────┐
│ Cross-Verification │ Consensus → confirmed finding.
│ │ Disagreement → UNCERTAIN flag, not hidden.
└─────────┬───────────┘
│ verdict + evidence
▼
┌─────────────────────┐
│ TrustReport │ Verdict (pass / review / reject) +
│ │ Confidence score + Findings +
│ │ SHA-256 evidence chain + Timestamp
└─────────────────────┘
The core insight: a single model cannot discover its own blind spots. Two models trained on different data, with an adversarial opponent actively trying to break the output, catch what either would miss alone.
One API key is enough. If you only provide OPENAI_API_KEY, the engine automatically falls back to gpt-4o-mini for the secondary auditor. Cross-provider (OpenAI + Anthropic) gives the strongest results because the models have different failure modes.
Why Not PR-Agent / CodeRabbit / Copilot
| PR-Agent / CodeRabbit / Copilot | ai-flow-architect | |
|---|---|---|
| Review model | Single model reviews in one pass | Two models + adversarial opponent cross-verify |
| False positives | Reported as-is. You triage manually. | Opponent Brain challenges and filters unconfirmed claims |
| Disagreement | Not applicable (single model, no dissent) | Flagged UNCERTAIN with both positions quoted — you decide |
| Evidence | A review comment in a PR thread | SHA-256 hashed, timestamped evidence chain. Tamper-proof. |
| Auditability | "Trust the bot said so" | Verifiable cryptographic proof of what was found and when |
The difference isn't "we're better." It's that single-model review has a fundamental ceiling: one model cannot reliably challenge its own conclusions. Adding an opponent changes the game.
HTML Reports
Export self-contained HTML reports with --html. Send them to your team. Post them in issues. Every share is an audit your AI didn't get away with.
ai-flow audit contract.pdf -r "Check for unfair terms" --html -o contract-audit.html
The report includes color-coded findings, arbiter votes with model attribution, collapsible evidence chains, and a transparent cost breakdown. No external CSS, no JavaScript frameworks, no server — one file, works everywhere.
TrustEngine
TrustEngine is the standalone audit layer. Zero state. Zero interaction. Pure verification.
report.verdict # "pass" | "review" | "reject"
report.confidence # 0-100
report.findings # Specific issues with severity + evidence
report.uncertainty # What the engine admits it cannot confirm
report.evidence_chain # SHA-256 hash + timestamp, fully verifiable
Output Formats
| Format | Command | Use Case |
|---|---|---|
| Terminal | ai-flow audit ... |
Interactive, color-coded |
| HTML | ai-flow audit ... --html -o report.html |
Share with team, post in issues |
| JSON | ai-flow audit ... --json |
Pipe to other tools, CI/CD |
| Markdown | ai-flow audit ... --markdown |
Embed in docs, PR comments |
Integrations
| Integration | Effort | Guide |
|---|---|---|
| CLI | 1 line | ai-flow audit ... |
| Python SDK | 3 lines | TrustEngine().audit(...) |
| LangChain | 3 lines | agent.run() + engine.audit() |
| CrewAI | 4 lines | crew.kickoff() + engine.audit() |
| OpenAI SDK | 5 lines | client.create() + engine.audit() |
| GitHub Action | YAML | Copy .github/workflows/ai-review.example.yml |
Comparison
| Feature | ai-flow-architect | Mira | Raw LLM |
|---|---|---|---|
| Open Source | ✅ | ❌ | — |
| Multi-model Arbitration | ✅ | ✅ | ❌ |
| Adversarial Review | ✅ | ❌ | ❌ |
| Uncertainty Transparency | ✅ | ❌ | ❌ |
| Verifiable Evidence Chain | ✅ | ❌ | ❌ |
| Cost | Free software; you pay for your own API keys | $X/month subscription | Free (trust at your own risk) |
Advanced: FlowArchitect
TrustEngine audits existing AI output. FlowArchitect builds the output under audit from the start. For when "review after generation" isn't enough — you want the opponent in the room during planning.
from ai_flow_architect import FlowArchitect
async def main():
architect = FlowArchitect(config={"brain1": "gpt-4o"})
result = await architect.run("Design a user management system")
# Brain #1 plans → Opponent challenges → You approve → Experts execute → Brain #2 audits
→ Full FlowArchitect documentation
Project Structure
ai-flow-architect/
├── src/ai_flow_architect/
│ ├── engine/ # TrustEngine — standalone audit layer
│ │ ├── trust_engine.py # Core audit interface
│ │ ├── trust_report.py # TrustReport schema + serialization (JSON/MD/HTML)
│ │ └── audit_context.py # AuditContext for project metadata
│ ├── brains/
│ │ ├── brain_one.py # Brain #1: requirement analysis + blueprint generation
│ │ ├── brain_two.py # Brain #2: quality arbitration (cross-model)
│ │ └── brain_opponent.py # Opponent Brain: 5 adversarial review styles
│ ├── core/
│ │ ├── architect.py # Three-phase orchestration + user approval loop
│ │ ├── scheduler.py # Serial execution + 4 token-saving mechanisms
│ │ ├── context.py # Session CRUD + history compression
│ │ └── cache.py # CRUD + TTL + hit stats
│ ├── experts/ # Expert team: creative, evaluator, programmer, reviewer
│ ├── utils/
│ │ ├── llm_client.py # Unified LLM client (8 providers)
│ │ ├── token_counter.py # Token counting + cost estimation
│ │ ├── compressor.py # Context compression (4 strategies)
│ │ └── validator.py # Input validation
│ └── templates/
│ └── report.html # Jinja2 template for --html export
├── tests/unit/ # 186 unit tests
├── docs/
│ ├── flow-architect.md
│ ├── getting_started.md
│ └── sample-report.html # Example TrustReport (open in browser)
├── .env.example
├── pyproject.toml
└── models.yaml # Provider + model configuration
Roadmap
- GitHub Action — Automated PR review comments with --html report links
- PyPI package —
pip install ai-flow-architect - Persona marketplace — Community-contributed adversarial review styles (
/personas) - Community showdown — "Can you beat our opponent brain?" challenge
- HTML report export — Self-contained, shareable audit reports
- CLI interface —
ai-flow auditwith--html,--json,--markdown - TrustEngine — Multi-arbiter + adversarial + evidence chain
- Model providers — OpenAI + Anthropic production-tested, 5 more via compatible protocol
- Parallel execution — Independent steps run concurrently
- Streaming output — Real-time expert output streaming
Comments