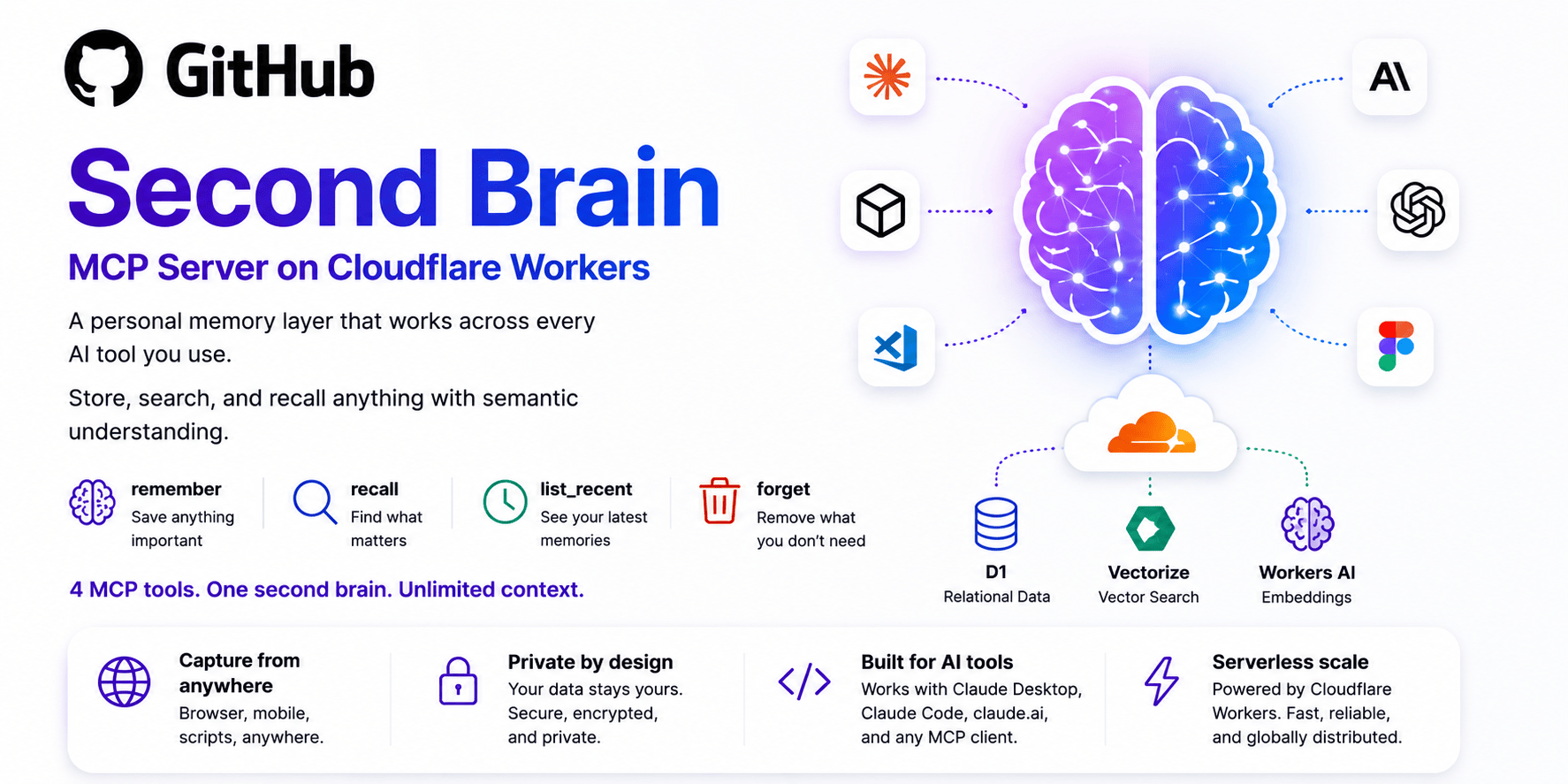
This project addresses a common challenge in information management: the need to store and recall data across multiple AI tools and platforms. The challenge lies in creating a unified memory layer that integrates with existing systems without requiring complex setup. The solution centers on a single memory layer that can be accessed by various AI interfaces, ensuring seamless retrieval through different clients. Developers and users alike are drawn to this project because it aims to simplify cross-platform data handling. The codebase is self-hosted and operates within Cloudflare’s free tier, making it accessible for a broad audience. With a solid foundation of community support and clear documentation, this initiative offers a practical approach to managing recollections across tools. The project is maintained with attention to detail, and its transparency is reflected in its active GitHub repository. Those seeking a lightweight, open-source alternative to fragmented memory solutions will find value in this effort.
Getting it running requires basic setup steps outlined in the README. Users should install the necessary dependencies using a standard package manager. The process is straightforward, involving only a few lines of command. A quick start is provided through a concise script that initializes the storage system. This approach ensures that even new contributors can integrate the project into their workflows without extensive training. The installation command is designed to be clear and executable in a development environment. For those unfamiliar with the command line, the instructions emphasize simplicity and reproducibility. It's worth noting that the project does not rely on proprietary libraries, sticking to open-source standards. This makes it ideal for teams focused on compliance and long-term maintainability.
When evaluating this tool against alternatives, it's clear that it occupies a niche where simplicity meets functionality. Users who prioritize stability over flashy features will appreciate its reliable performance. Those looking to avoid vendor lock-in benefit from the self-hosting capability. The project’s design encourages careful consideration of use cases before implementation. If you're exploring options for centralized recollection management, this solution warrants attention. You can find more details on the project’s website at second-brain-cloudflare.
The limitations of this implementation are worth noting. The current scope restricts the depth of data persistence, and integration with newer AI models may require future updates. However, the active development process indicates ongoing refinement. This balance between breadth and depth ensures that the project remains relevant for its target audience. Whether you're managing notes, project histories, or tool preferences, the second-brain-cloudflare offers a structured path forward. The source is available for review at the project’s GitHub page.
Comments