gepa-research is a Python-based plugin designed to integrate with agentic development frameworks and automate code optimization using the GEPA algorithm—short for Genetic-Pareto LLM-driven search. It does not rewrite code directly. Instead, it acts as a bridge: given a codebase, it identifies measurable objectives (like latency, memory usage, or test pass rate), sets up evaluation infrastructure, and delegates the search for better implementations to the external gepa library. That library implements an evolutionary optimizer guided by LLM reflection, maintaining a Pareto frontier of non-dominated candidates and using diagnostic feedback to propose targeted changes. The project targets developers and researchers building or extending agent systems—especially those already using Claude Code, Codex, OpenClaw, or Hermes—and aims to reduce manual iteration when optimizing performance-critical code paths.
Core features
- GEPA-backed search loop: Relies on
gepa.optimize_anythingfor the inner optimization. This includes LLM-driven reflection over execution traces, automatic Pareto selection, and built-in stall detection and budget enforcement (e.g., limiting evaluator calls to 50 by default). - Isolated candidate evaluation: Each proposed code variant is applied in a separate Git worktree, committed only if it passes configured gates—preserving full version history and enabling deterministic rollback.
- Gating system: Supports arbitrary Python-callable checks (e.g., regression test suites or safety linters). Candidates failing a gate receive a score of 0.0 and are excluded from the Pareto frontier.
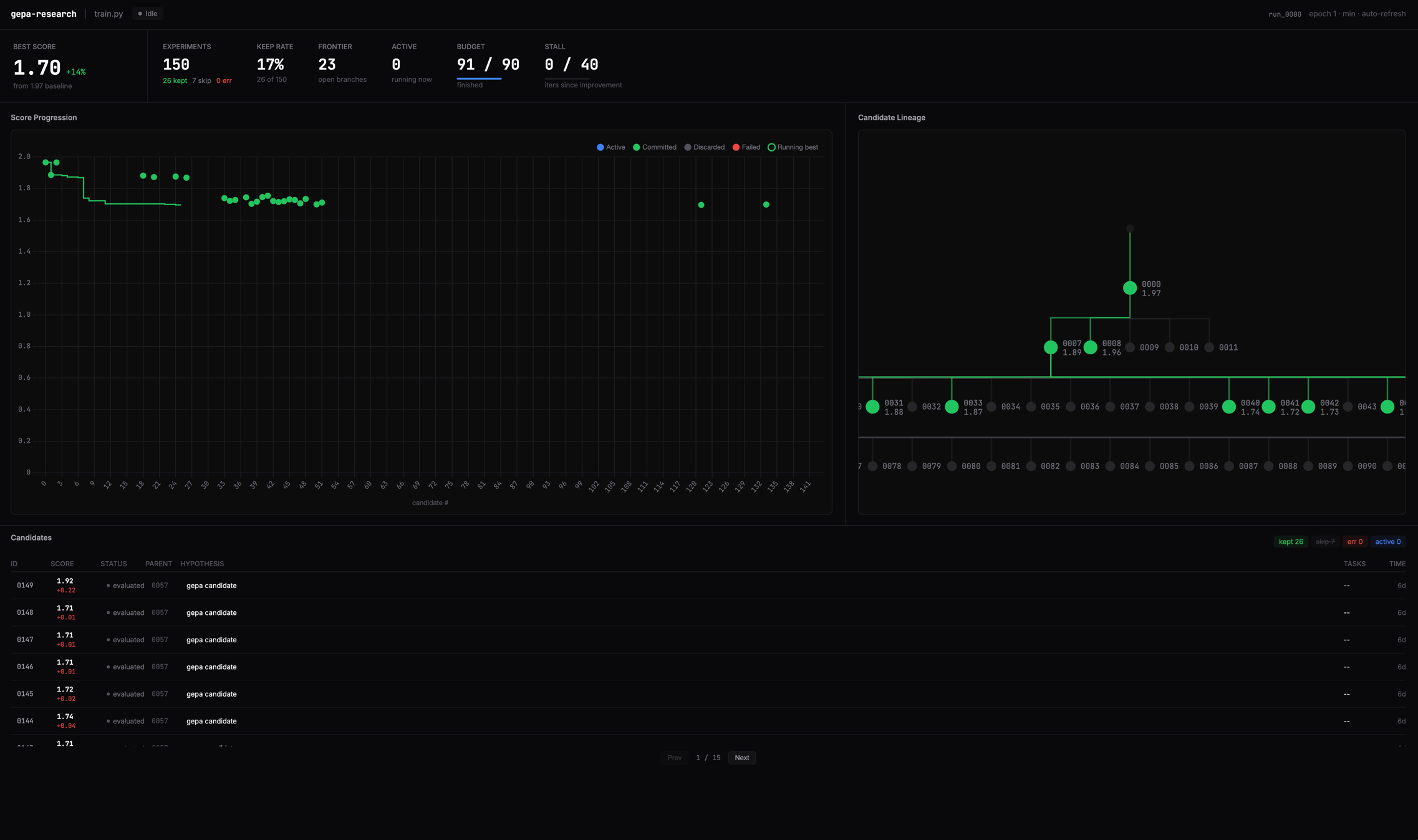
- Observability dashboard: A local web interface renders the candidate lineage as a DAG (using
GEPAResult.parents) and displays per-task execution traces, helping users trace how improvements emerged. - Automatic benchmark discovery: The
discoverskill inspects the repository structure, infers relevant metrics, and auto-instruments evaluation—no manual benchmark definition required to start.
Getting it running
The plugin ships as a CLI tool and supports four host frameworks. Python 3.10+ and git are required. uv is the recommended installer, though pipx works as well. Installation differs depending on the host:
For Codex, OpenClaw, and Hermes, install the CLI first:
uv tool install "git+https://github.com/CyrusNuevoDia/gepa-research#subdirectory=plugins/gepa-research"
# or
pipx install "git+https://github.com/CyrusNuevoDia/gepa-research#subdirectory=plugins/gepa-research"
Then follow host-specific plugin registration:
Codex (requires 0.121.0-alpha.2 or newer):
codex marketplace add CyrusNuevoDia/gepa-researchAfter installing via
/plugins, invoke with$gepa-research discoveror$gepa-research optimize.OpenClaw:
openclaw plugins install gepa-research --marketplace https://github.com/CyrusNuevoDia/gepa-researchCommands:
/discover,/optimize.Hermes: Install skills individually:
hermes skills install CyrusNuevoDia/gepa-research/plugins/gepa-research/skills/discover --force hermes skills install CyrusNuevoDia/gepa-research/plugins/gepa-research/skills/optimizeUse
/discoverand/optimize.Claude Code bundles its own copy. Install via:
/plugin marketplace add CyrusNuevoDia/gepa-research /plugin install gepa-research@CyrusNuevoDia-gepa-researchThen run
/gepa-research:discoveror/gepa-research:optimize.
The optimize command accepts optional parameters like max-metric-calls=50 (total evaluator invocations) and stall=5 (number of consecutive generations without improvement before stopping).
Who this is for
This tool is intended for developers working inside agent-centric coding environments who want to automate empirical code improvement—not just code generation. It fits teams already using Claude Code, Codex, OpenClaw, or Hermes and are comfortable with Git workflows and Python-based evaluation logic. Use cases include optimizing hot loops in Python services, reducing memory footprint in data pipelines, or improving latency in inference wrappers—especially when trade-offs between speed, correctness, and resource use must be navigated. It assumes users can define or accept auto-discovered evaluation criteria, and that the target codebase has test coverage or other deterministic gates.
How it comparesgepa-research is narrower in scope than general-purpose LLM code agents like devon or smolagent, which handle broader tasks like issue triage or documentation. It also differs from static analysis tools (e.g., pylint, ruff) or traditional profilers (cProfile, perf)—it does not just measure or suggest; it searches across code variants with LLM-guided mutation. Unlike llm-code-search or code-t5-based optimizers, it relies on external LLMs (via supported hosts) and couples tightly with GEPA’s evolutionary logic. It is heavier than simple prompt-based refactor plugins—requiring Git, Python evaluation hooks, and a running dashboard—but provides more rigorous, auditable optimization than ad-hoc LLM edits. At 81 GitHub stars and written in Python, it sits in early-adopter territory: functional, documented, and framework-specific—not a general SDK.
The project is hosted at https://github.com/CyrusNuevoDia/gepa-research and depends on the upstream GEPA implementation at https://github.com/gepa-ai/gepa.
Comments