A local budget guardrail for AI agents. It hard-stops your agent before its next LLM call when it would cross a spend ceiling — so a runaway loop dies at $0.10 instead of $4,000. No account, no signup, no network. Runs in your process.
pip install floe-guard
from floe_guard import BudgetGuard
guard = BudgetGuard(limit_usd=5.00) # your ceiling
guard.check() # before each LLM call — raises if it'd cross
response = call_your_llm(...) # your existing call
guard.record("gpt-4o", response.usage.prompt_tokens, response.usage.completion_tokens)
When the next call would cross the ceiling, the guard raises BudgetExceeded and
prints:
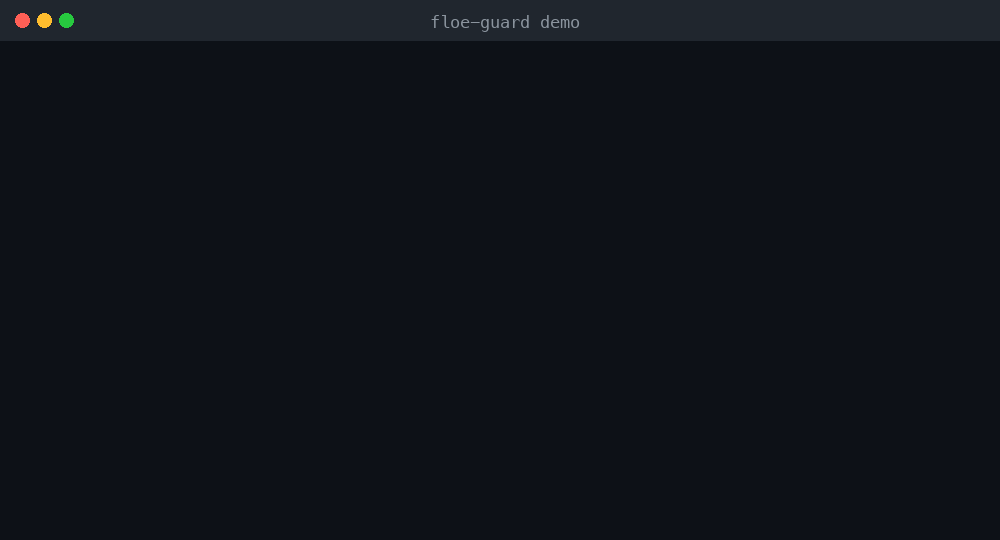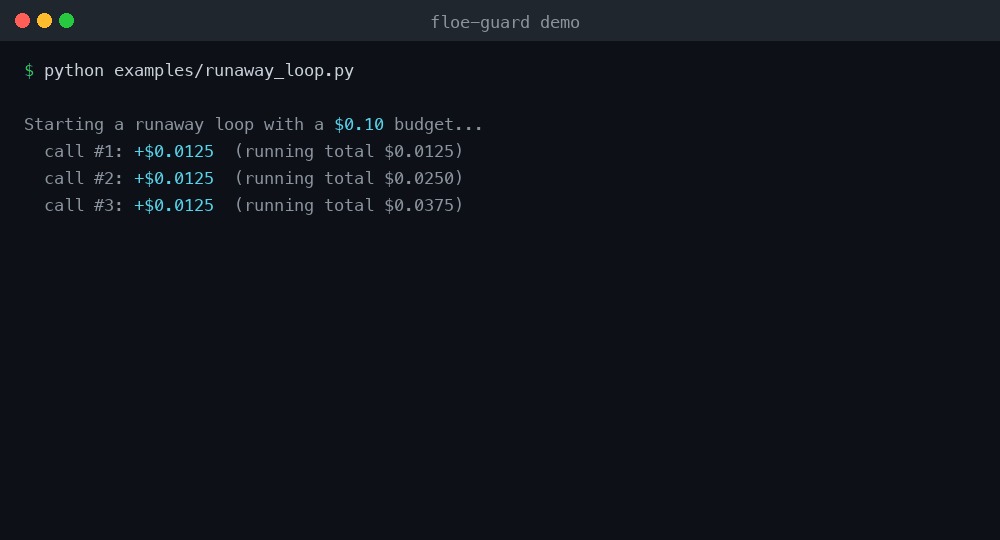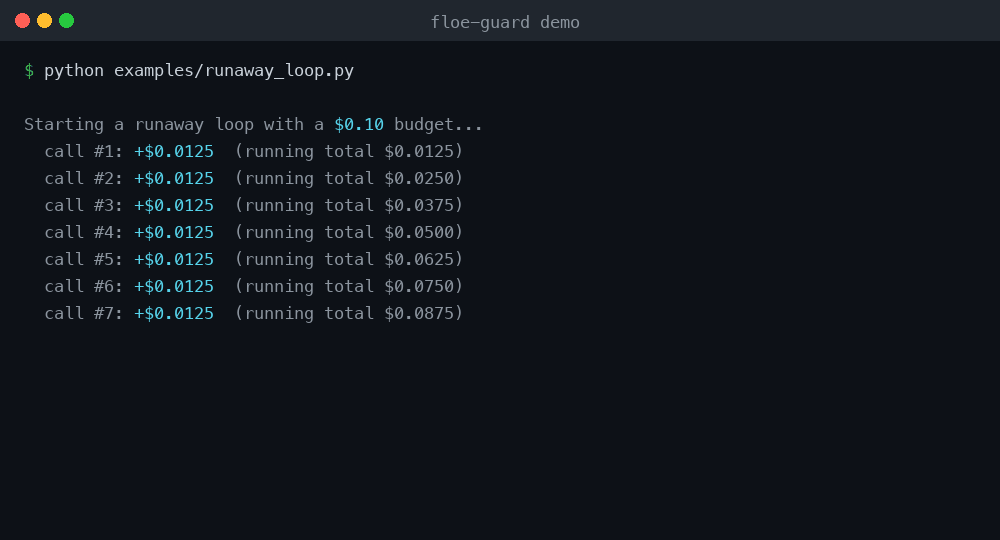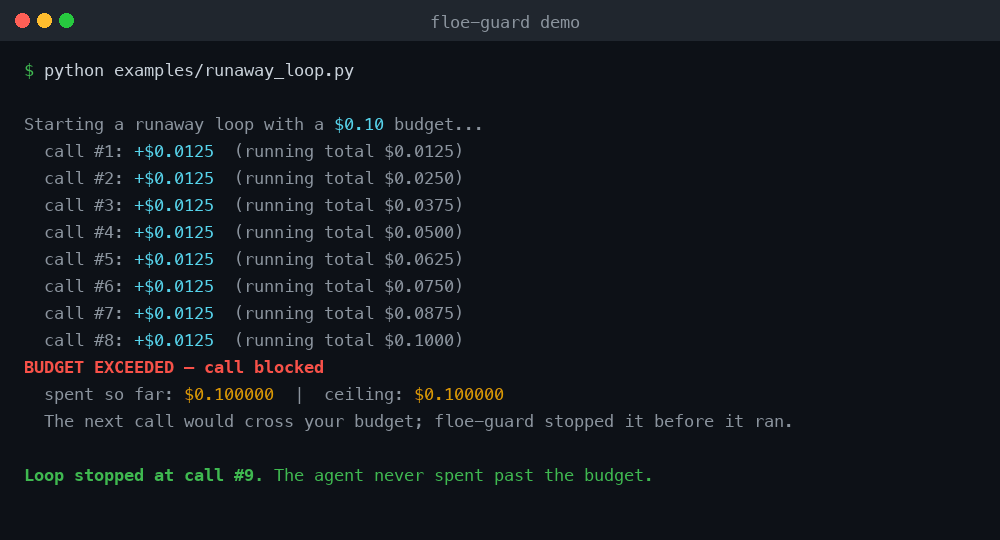
BUDGET EXCEEDED — call blocked
spent so far: $5.001250 | ceiling: $5.000000
The next call would cross your budget; floe-guard stopped your agent before it ran.
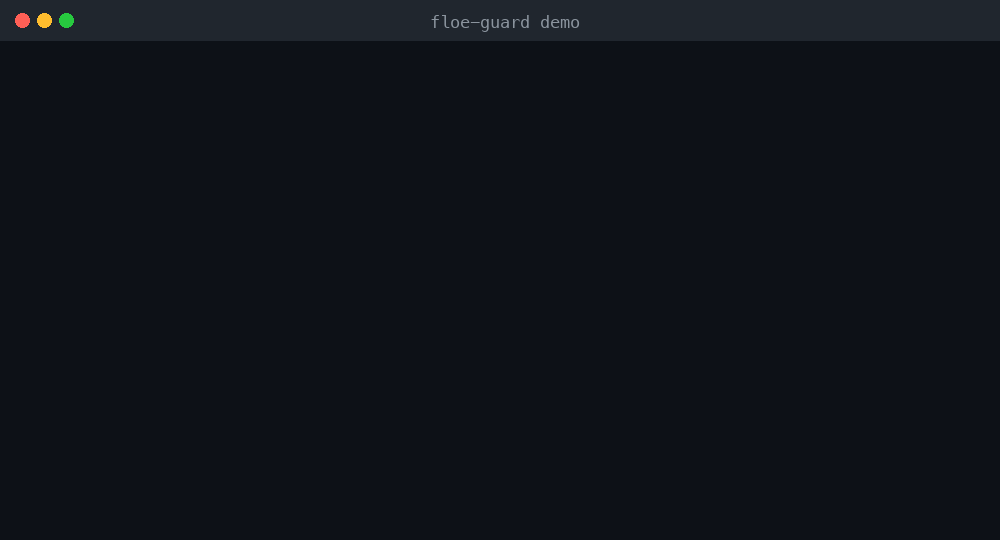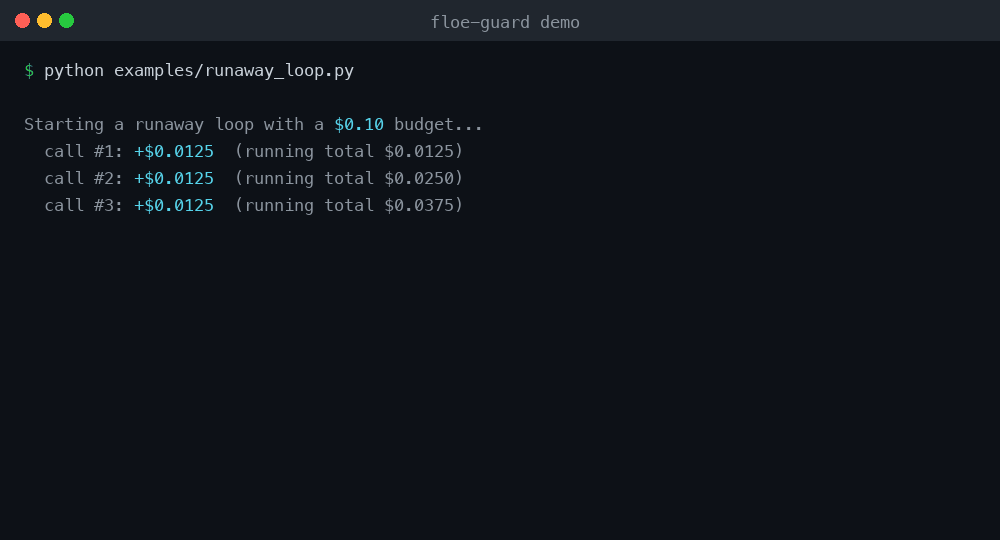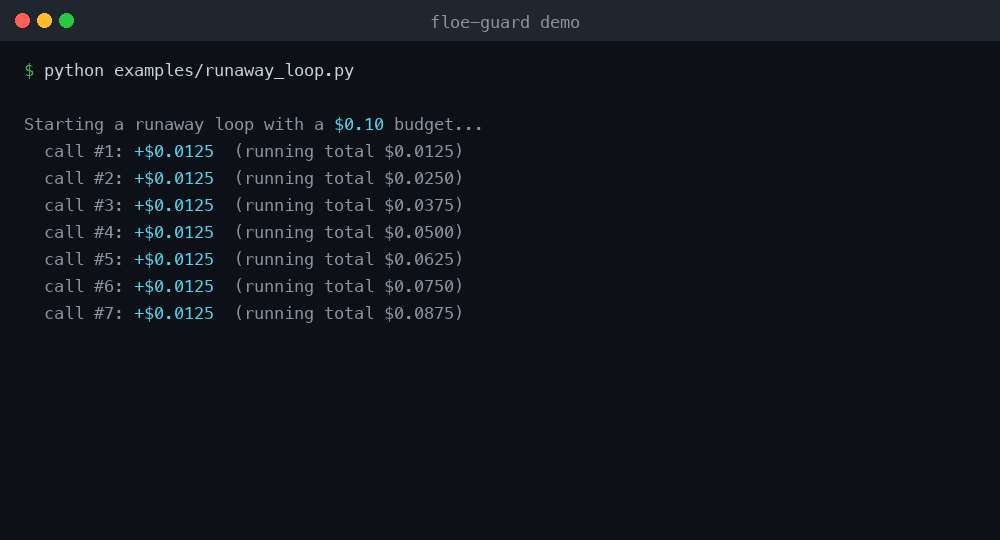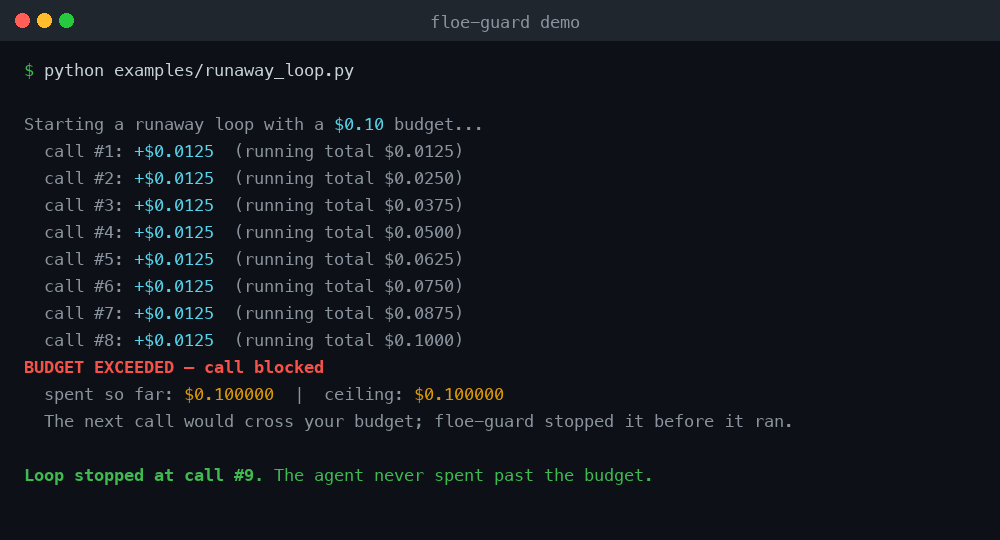
Run it yourself: python examples/runaway_loop.py — no API key, no account, no network.
See it stop a loop (no API key needed)
python examples/runaway_loop.py
This rigs a loop against a stub LLM — no real API key, no account, no network.
It prices each fake gpt-4o call offline and the guard halts the loop after a few
iterations. This is the reproducible "stop the loop" demo.
Why floe-guard?
You can already see what your agent spends — the problem is seeing it too late. floe-guard is the part that stops the call, not the part that reports the damage.
max_tokens/max_rpmcap size and rate, not dollars — a cheap model stuck in a loop still drains the budget.- Usage logs and provider dashboards tell you what you spent after it's gone. floe-guard refuses the call before it crosses your ceiling.
- A cost callback that just logs is notified after the fact and can't halt the run — enforcement has to stand in front of the next call. That's where it lives.
- A hand-rolled
spent += costcounter races under parallel agents (CrewAI fan-out,asyncio,Promise.all): N calls read the same under-limit total and all fire. floe-guard reserves atomically (reserve()/settle()), so the ceiling holds under concurrency.
The whole job: a hard stop before the next call, that holds under fan-out — no account, no network, no crypto.
How it works
The guard sits in the call path, not on an event bus. A passive listener is told about spend after the fact and can't halt anything — so enforcement has to be the thing standing in front of the next call:
check()runs before each LLM call. It predicts the next call's cost from the last one and raisesBudgetExceededif that would cross your ceiling — the call never runs. (A running-total check also catches an overshoot if an estimate came in low.)record(model, prompt_tokens, completion_tokens)runs after each response. It prices the tokens offline from a bundled LiteLLM cost map and adds the USD to a running total.
Unpriceable models fail closed
If a model isn't in the cost map and you didn't supply a price, the guard warns
loudly and refuses (UnpriceableModelError) rather than silently treat it as
free — you can't cap spend you can't measure. Give it a price to enforce it:
from floe_guard import BudgetGuard, ManualPrice
guard = BudgetGuard(
limit_usd=5.00,
price_overrides={"my-self-hosted-model": ManualPrice(1e-6, 2e-6)}, # USD/token
)
# or, set fail_closed=False to warn-and-skip for models you accept un-metered.
Context-aware budgeting
The hard-stop is the guarantee; advisory() is the upside. Read it before a
step to let your agent adapt as it nears the cap — taper to a cheaper model,
shrink the task, or wrap up — instead of getting cut off mid-run.
guard = BudgetGuard(limit_usd=0.10, near_limit_bps=7000) # flag at 70% used
adv = guard.advisory()
# BudgetAdvisory(near_limit=False, used_bps=125, remaining_usd=0.0987, ...)
model = "gpt-4o-mini" if adv.near_limit else "gpt-4o" # downshift near the cap
guard.check() # still the hard line — taper or not, this holds
response = call_your_llm(model)
guard.record(model, response.usage.prompt_tokens, response.usage.completion_tokens)
advisory() returns near_limit, used_bps (utilization in basis points),
remaining_usd, and the budget totals. It's a soft signal — the model may
ignore it; check() is what enforces the ceiling. See
examples/budget_aware.py for a runnable taper demo
(no API key).
This is the same advisory shape hosted Floe returns on every proxied call
(the X-Floe-Budget-Advisory header), so the logic you write here ports
unchanged — hosted just answers across every vendor and cap with server-truth
balances and rolling-window reset timing, which a single local budget can't know.
The TS package exposes the identical guard.advisory().
Framework adapters (optional extras)
CrewAI
pip install floe-guard[crewai]
from crewai import Crew
from floe_guard import BudgetGuard
from floe_guard.integrations.crewai import guard_crew
guard = BudgetGuard(limit_usd=1.00)
guard_crew(guard) # one line — enforces across the whole crew
Crew(agents=[...], tasks=[...]).kickoff()
CrewAI runs on LiteLLM, so one callback caps every agent and task under a single budget.
LiteLLM
pip install floe-guard[litellm]
from floe_guard import BudgetGuard
from floe_guard.integrations.litellm import guarded_completion
guard = BudgetGuard(limit_usd=1.00)
response = guarded_completion(guard, model="gpt-4o", messages=[...])
Prefer the LiteLLM-native callback? Register budget_guard_callback(guard) on
litellm.callbacks.
LangChain
pip install floe-guard[langchain] langchain-openai # langchain-openai only for the ChatOpenAI example below
from langchain_openai import ChatOpenAI
from floe_guard import BudgetGuard
from floe_guard.integrations.langchain import budget_guard_callback_handler
guard = BudgetGuard(limit_usd=1.00)
llm = ChatOpenAI(model="gpt-4o", callbacks=[budget_guard_callback_handler(guard)])
llm.invoke("hello") # checks budget before the call, records spend after
The handler checks the budget on LLM start (raising BudgetExceeded aborts the
call before it runs) and records token usage on LLM end.
Vercel AI SDK
The Vercel AI SDK is TypeScript-only, so it ships as a separate npm package that
lives in js/.
npm i floe-guard ai@4 @ai-sdk/openai
import { wrapLanguageModel } from "ai";
import { openai } from "@ai-sdk/openai";
import { BudgetGuard, budgetGuardMiddleware } from "floe-guard";
const guard = new BudgetGuard(5.0); // your ceiling, in USD
const model = wrapLanguageModel({
model: openai("gpt-4o"),
middleware: budgetGuardMiddleware(guard), // throws before crossing
});
The middleware check()s before each call (throwing BudgetExceeded to halt the
run) and record()s priced usage after — same semantics as the Python guard. See
js/README.md.
Honest about what this is
floe-guard is a local, estimate-based guardrail. It prices tokens from a vendored cost map inside your process:
- The cost map can drift as vendors change prices — refresh it like any snapshot.
- It only sees the vendors you instrument.
- A determined agent or a bug could route around an in-process check.
- Under heavy or cold-start concurrency it bounds steady-state spend, not the
first parallel wave. Reservations size from the last call's cost (
0until the firstrecord()), so the opening fan-out has nothing to estimate from. Pass a known per-call max toreserve()to bound it, or use hosted Floe for a hard cap under arbitrary concurrency.
It's genuinely useful on its own, and it's honest about its limits. No inflated metrics, no "zero defaults" claims — it's a free local stop, not a vault.
Upgrade to hosted Floe
When you need the ceiling to be un-bypassable and cross-vendor, hosted Floe moves enforcement server-side against a real credit line:
- Un-bypassable — enforced at the spend rail, not in your process.
- Cross-vendor — one budget over LLM tokens and paid (x402) tool calls.
- Team budgets + analytics — shared ceilings, per-agent isolation, spend history.
Set FLOE_API_KEY (your agent key, floe_<hex>) and floe-guard can read your
agent's server-side remaining budget from the live Floe endpoint:
from floe_guard import hosted_enforcement_available, hosted_remaining_usd
if hosted_enforcement_available(): # True when FLOE_API_KEY is set
remaining = hosted_remaining_usd() # USD left, read from Floe's server
hosted_remaining_usd() GETs /v1/agents/credit-remaining and returns the USD
remaining — the minimum of your auto-borrow headroom and your session spend
remaining. It raises HostedEnforcementError on a bad/missing key (401), a
closed or suspended agent (403), an unprovisioned agent (404), or a network
failure.
Env vars:
FLOE_API_KEY— your agent key. Required for the read.FLOE_API_BASE_URL— override the API host (defaults tohttps://credit-api.floelabs.xyz).
Honest scope: this call only reads the remaining budget. The un-bypassable, cross-vendor enforcement is the hosted Floe product running server-side — not this client. Use the number to inform a local ceiling; the server stays the source of truth.
→ dev-dashboard.floelabs.xyz · floelabs.xyz
Built with floe-guard
Using floe-guard in your project? Add the badge so others find it:
Development
pip install -e ".[dev]"
pytest
ruff check .
Comments