Librarry is a self-hosted book manager for ebooks and audiobooks. It is designed as a modern Readarr replacement with a stronger metadata foundation, explicit provider provenance, and first-class support for manual correction when upstream book data is incomplete or ambiguous.
Status: early alpha. Librarry is being built as a Readarr replacement, not a qBittorrent, Transmission, or SABnzbd replacement. The primary workflow is metadata-first library management: search and normalize book metadata, monitor authors, mark books wanted, evaluate releases, import files into ebook and audiobook libraries, and preserve manual corrections when provider data is wrong.
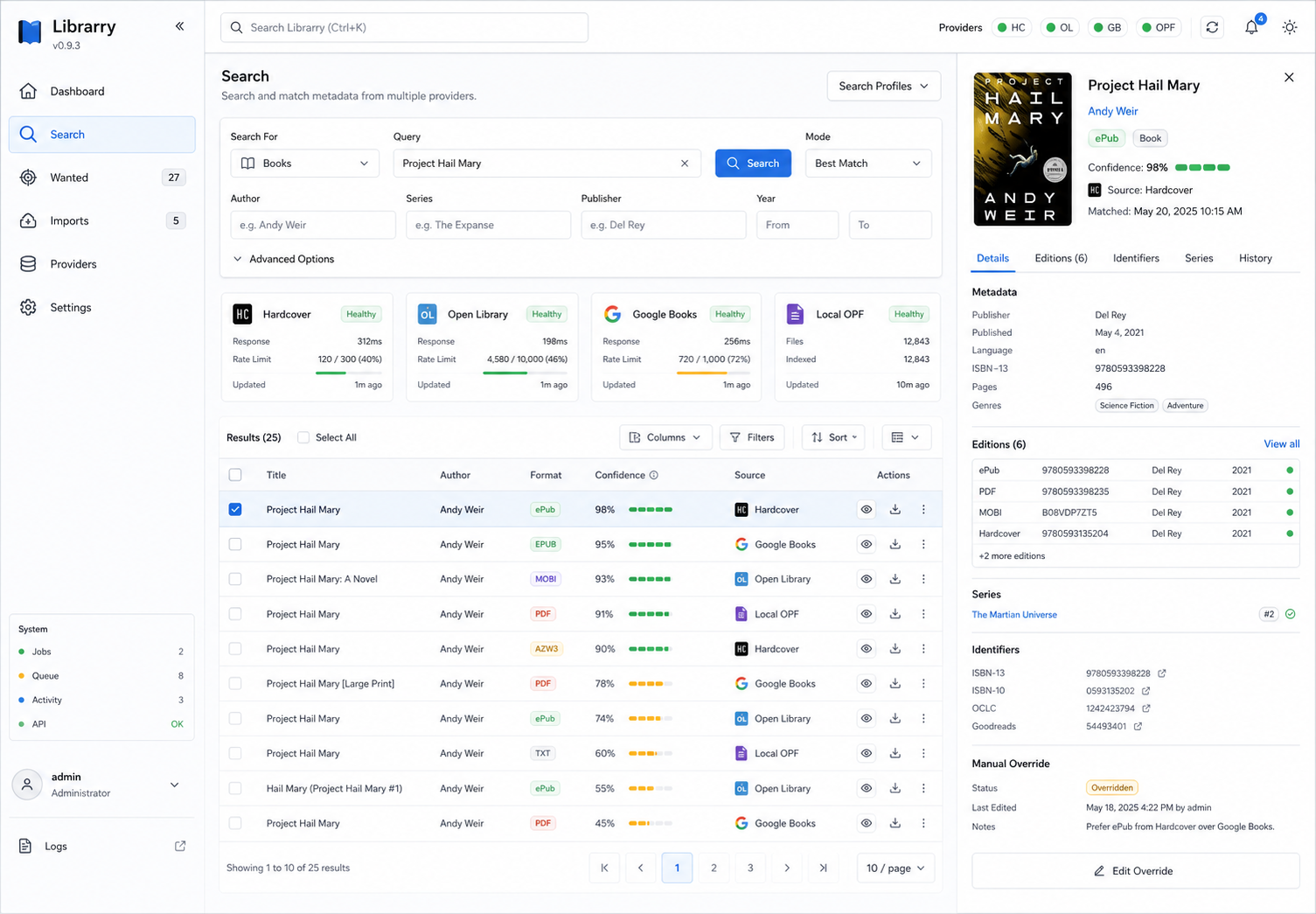
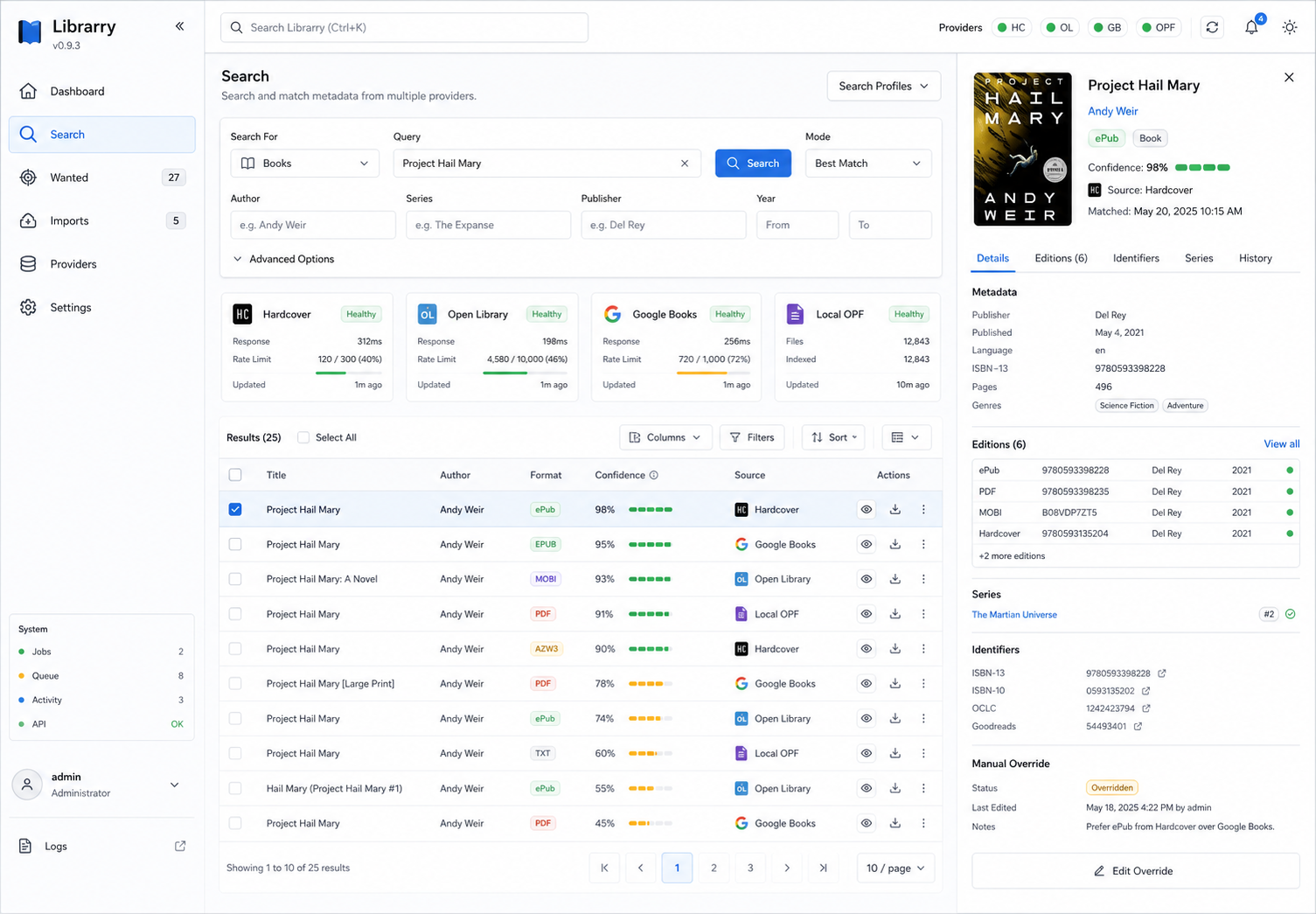
The current build has real metadata search, provider health, a Library-first UI, wanted books, author subscriptions, persisted quality profiles, release-decision review, Prowlarr-backed search/feed sync, configured-root and ad hoc library scan, manual and completed-download import, Readarr migration preview/import, Calibre Content Server handoff, Readarr-compatible author/book/wanted/import/history/config routes, and durable manual overrides for title, author, cover, quality profile, language, publisher, published date, series, series position, ISBN, and monitoring state.
Download clients are deliberately supporting infrastructure. Librarry can send approved book releases to configured clients and expose scoped book-acquisition controls for queues, files, trackers, categories, tags, recovery, and import handoff. It is not intended to replace the full native UI of qBittorrent, Transmission, or SABnzbd.
Project Status
Librarry is early alpha. The current implementation is strong enough to test the metadata-first Readarr replacement workflow, but it is not yet a drop-in production replacement for an unattended Readarr instance.
Current verified highlights:
- Open Library metadata search, provider provenance, deduped/merged search results, wanted items, manual metadata overrides, release decisions, and the Library-first UI are implemented.
- Prowlarr release search and qBittorrent book-acquisition handoff have been tested against a live deployment.
- The live TrueNAS/Cosmos deployment path has been exercised with Postgres,
local Docker images, and the
media-stackmount.
Current gaps:
- Hardcover and Google Books need credentials in the live deployment.
- A real Readarr migration dry run, real book-root scan, and full wanted-to-import loop still need controlled validation before relying on Librarry as the only book automation system.
- Published versioned container images and release artifacts are not available yet.
See docs/status.md for the current work status, verified deployment notes, and known gaps.
Documentation
- Current status: what works, what is risky, and what needs validation next.
- Local development: run commands, configuration, Docker Compose, TrueNAS, integrations, and worker settings.
- Architecture: backend/frontend/Postgres structure and API surfaces.
- Metadata strategy: provider order, matching policy, and excluded data sources.
- Provider setup: Hardcover, Open Library, Google Books, and local metadata configuration.
- Agent guide: repo-specific instructions for future coding agents.
Why Librarry?
Book automation is harder than movie or TV automation because metadata is messy: works, editions, formats, narrators, translations, ISBNs, series order, and publisher data frequently disagree across providers. Librarry treats that as the core product problem instead of hiding it behind one fragile upstream source.
The project goals are:
- keep a local canonical model for authors, works, editions, series, files, releases, downloads, and manual overrides;
- preserve raw provider records so matches can be explained and corrected;
- support ebooks and audiobooks without collapsing them into one target;
- make manual overrides durable and higher priority than every provider;
- provide Readarr-style workflows and API compatibility while leaving torrent and Usenet client administration to the external clients built for it;
- integrate with existing self-hosted media stacks instead of replacing them.
Download Client Boundary
Librarry is not a full torrent manager and does not try to replace the native qBittorrent, Transmission, or SABnzbd interfaces. It owns the book workflow: which book is wanted, which release was acceptable, which external client got the job, whether the completed files match the wanted item, and how those files are imported into the library.
The Downloads view is therefore scoped to acquisition work that matters to a Readarr replacement:
- add a book download from a magnet, torrent file, torrent URL, or NZB URL;
- inspect Librarry-tagged jobs or all jobs returned by configured clients;
- start, stop, remove, recheck, reprioritize, rename, move, tag, and recategorize jobs when the external client supports the action;
- inspect files, trackers, peers, category/tag resources, and basic client preferences for diagnosing book jobs;
- import completed jobs, recover failed jobs, and preserve history around the book acquisition.
For general torrent administration such as global rules, plugin management, advanced ratio policies, non-book downloads, peer banning, tracker-wide tuning, or detailed client settings, the external client remains the source of truth.
Librarry vs. Readarr
Readarr is the obvious reference point, but it has been retired by the Servarr team and its repository is archived. The official retirement note cites unusable metadata, limited maintainer time, and a stalled Open Library transition. Readarr remains much more complete as an automation app today; Librarry is an early replacement focused first on fixing the metadata model.
| Capability | Readarr | Librarry today | Librarry direction |
|---|---|---|---|
| Project status | Retired and archived; existing installs may continue but upstream development has stopped. | Active early alpha. | Public, maintained replacement with a smaller but durable core. |
| Readarr migration | Source application; state is managed in the existing Readarr database and API. | Settings UI and native API can preview and import an existing Readarr instance's quality profiles, tags, root folders, authors, books, book files, import lists, import-list exclusions, profiles, metadata consumers, custom formats, restrictions, notifications, remote path mappings, download clients, and indexers into Librarry quality profiles, compatibility resources, root folders, author subscriptions, wanted items, and tracked library files. Imported author/book tags are preserved for restriction scoring. | Expand migration to include history, queued activity, and richer edition preservation. |
| Metadata source model | Historically depended on centralized metadata; the retirement announcement names metadata failure as the blocking issue. | Multi-provider abstraction with Hardcover, Open Library, Google Books fallback, and local metadata stubs. | Local canonical graph with provider provenance, explainable matches, and resilient fallback behavior. |
| Manual correction | Supports normal app-level editing workflows. | Native wanted-item editor and provider-provenance UI can correct title, author, cover URL, quality profile, language, publisher, published date, series, series position, ISBN, and monitoring state. Corrected metadata writes manual_overrides rows, provider refreshes preserve protected fields, visible override chips can reset individual fields, and a whole provider record can be promoted in one review action. |
Expand correction to the full author/work/edition graph, embedded file metadata writes, and larger batch review workflows. |
| Ebook and audiobook handling | Supports ebooks and audiobooks, but Readarr notes that one type of a given book requires one instance; both formats require multiple instances. | Data model and acquisition categories are format-aware for ebooks and audiobooks. | One app should manage both formats without collapsing editions or file targets. |
| Library import | Mature library scan and missing-book detection. | Configured ebook/audiobook roots and ad hoc root paths can be scanned from the Imports UI for ebook/audiobook files; OPF sidecars, embedded EPUB package metadata, MP3 ID3 tags, and M4B/MP4 metadata atoms are extracted during scan/import, files are tracked in Postgres, manual/completed import supports copy, move, hardlink, hardlink-or-copy, keep-both, replace, skip, and fail conflict decisions, completed Librarry-tagged downloads feed the library, unlinked completed downloads can auto-import when there is one high-confidence ISBN match from provider records or protected overrides, or one title/author/format wanted match; ambiguous downloads are queued for individual or bulk review with explainable file, local-metadata, filename, download-context evidence, wanted-item suggestions, and an explicit wanted-match chooser before import, and Readarr-compatible missing pages suppress wanted items already present in tracked files. | Add broader profile-aware automatic import matching and stronger rollback. |
| Wanted automation | Mature author/book monitoring, RSS monitoring, automatic grabs, failed-download handling, upgrades, sorting, and renaming. | Wanted queue, author subscriptions with all/future/none missing-book policies, metadata search, persisted quality profiles, Readarr-compatible release restrictions including tag-scoped rules for tagged wanted items, release evaluation, author/book tag persistence with bulk add/remove/replace editor modes, manual/interval wanted monitoring, scheduled author metadata sync, feed-based indexer sync, import-list sync into monitored wanted items, failed-download replacement search/grab, score-based upgrade search/grab, optional paused auto-grab, history, provider health, integration bootstrap, qBittorrent/Transmission/SABnzbd grabs, download reconciliation, actionable book-first acquisition queue states, file rename previews/apply, import conflict policies, bulk import-review resolution with evidence, and bulk selected-download actions. | Add deeper conflict reporting and broader review controls. |
| Manual release search | Mature manual search with rejection reasons and direct send to download clients. | Prowlarr-backed wanted release search with score/rejection reasons, native persisted Prowlarr/download-client settings, protected ISBN-first search terms, protected language-aware scoring, stored release-decision reload, approved/rejected review filters, explicit force-grab for manually selected rejected candidates, paused grab endpoint, manual magnet/torrent-file/torrent-URL/NZB add, stateful Readarr-compatible /api/v1/release search/grab adapter that can grab a persisted decision by returned Arr ID, scoped qBittorrent/Transmission controls, and SABnzbd add/list/start/stop/delete support for NZB releases. |
Add richer rejection explanations, quality scoring, and broader review queues. |
| Indexers | Native Readarr indexer support plus common Arr ecosystem patterns. | Prowlarr-compatible search client. | Keep Prowlarr as the preferred indexer aggregator instead of duplicating every indexer implementation. |
| Download clients | Supports SABnzbd, NZBGet, qBittorrent, Deluge, rTorrent, Transmission, uTorrent, and others. | Integrates with qBittorrent, Transmission, and SABnzbd as external book-acquisition targets. The native Downloads page is intentionally scoped to Readarr-style jobs: manual add, Librarry-tagged or all-client queue visibility, start/stop/delete/recheck, completed-download import, failed-download recovery, and enough file/tracker/category/tag controls to diagnose a book acquisition. It is not a general torrent or Usenet client administration UI. | Keep clients as replaceable integrations behind small interfaces while Readarr parity work focuses on metadata, monitoring, release decisions, imports, naming, and compatibility APIs. |
| API compatibility | Readarr exposes the standard Arr /api/v1 API for clients and tooling. |
Compatibility shim covers optional Readarr-style API-key auth, common probes and read paths: ping, system status, health, diskspace, Postgres-backed root folders with Calibre settings, resource catalogs, and config records for naming/media-management/host/UI/indexer/download-client settings; calendar, history, parse, queue, blocklist/blacklist, durable author/book list/create/update/delete compatibility, bookfile list/get/update/delete compatibility, rename and retag preview/apply flows, and native-backed command handling for RSS sync, missing search, book search, author search, failed-download recovery, upgrade/cutoff-unmet search, rename/rescan, and database-backed retag state; manual import, missing wanted books, quality profiles, quality definitions, delay profiles, language/metadata profiles, tags, custom formats, restrictions, Webhook notifications with native delivery, import lists, remote path mappings, system tasks, download clients, indexers, release search/grab, plus schema/test/action/bulk routes for common configurable Arr resources. | Expand toward full OpenAPI compatibility, including deeper native config side effects, embedded metadata writes, Calibre content-server operations, and broader native behavior behind compatibility resources. |
| Calibre integration | Supports Calibre library integration and conversion through Calibre Content Server. | Readarr-style Calibre root-folder settings are accepted, validated, persisted, and returned. Imports that land under a Calibre-enabled root are posted to the Calibre Content Server add-book endpoint, store the returned Calibre ID, push basic title, author, and identifier metadata through set-fields, start configured output-format conversions, and refresh conversion status through native API, command calls, or scheduled background polling. Physical deletes for Calibre-backed files call the Content Server delete-books endpoint. Richer edition metadata, embedded metadata writes, path refresh after Calibre renames, and failed-import rollback are not implemented yet. | Implement richer metadata sync, embedded metadata writes, path refresh after Calibre-side changes, and stronger error recovery behind the same root-folder contract. |
| Post-download organization | Mature sorting and renaming. | Completed Librarry-tagged downloads can be imported into format-aware ebook/audiobook roots, mark wanted items imported, use configurable naming templates, choose copy/move/hardlink mode and duplicate-file behavior, queue unlinked files for individual or bulk review, and rename tracked files through native or Readarr-compatible APIs. | Add richer matching evidence and per-profile organization rules. |
| Deployment | Windows, Linux, macOS, NAS, and Docker guidance; no official Docker image according to Readarr docs. | Docker Compose and TrueNAS custom-app templates. | Publish versioned container images and release artifacts. |
| License | GPL-3.0. | AGPL-3.0. | Keep network-service modifications available to users. |
Sources: Readarr GitHub repository, Readarr website, and Servarr Readarr wiki.
Current Features
- Go backend with REST APIs for health, metadata search, settings validation, provider diagnostics, release search, integration bootstrap, paused grabs, and download status.
- React and TypeScript web UI with dedicated views for provider health, metadata search, missing-focused wanted queue management, downloads, imports, settings, and operations history.
- Operations dashboard review inbox for the book workflow: metadata conflicts, skipped author candidates, unmatched import reviews, blocked acquisitions, and failed downloads are surfaced with direct navigation or recovery actions.
- Metadata search supports both book candidates and direct author identities, so an author can be monitored from a provider-backed author record without first selecting one of their books.
- Metadata search result rows and details expose edition-level evidence before acquisition: format, language, publisher/date, ISBN/ASIN identifiers, series position, provider confidence, and matched fields are visible before marking a book wanted. Provider, confidence, and evidence filters make ambiguous result sets easier to narrow before creating wanted items, and selected candidates show score, source identity, matched-field, and edition-evidence summaries. Equivalent candidates from multiple providers are clustered by ISBN or normalized title/author evidence, then shown as one result with contributing source names and merged provider IDs so corroboration strengthens the match without hiding provenance. Medium, low-confidence, or weak-evidence candidates require explicit review confirmation before they are marked wanted. Candidates already tracked as wanted open the existing wanted item instead of creating duplicates.
- Newly monitored authors are immediately eligible for a targeted bibliography refresh, which creates or reviews wanted books from metadata before release acquisition starts.
- Native integration settings API and UI for persisted Prowlarr, qBittorrent, Transmission, and SABnzbd configuration. Saved settings reconfigure the running acquisition service and are loaded again on restart.
- Native library settings API and UI for persisted ebook/audiobook import roots and naming templates. Saved settings reconfigure scans, imports, and rename previews immediately, are written as Readarr-compatible root-folder and naming config records, and are loaded again on restart.
- Readarr migration API and Settings UI that preview and import quality profiles, tags, root folders, authors, books, book files, import lists, and import-list exclusions from an existing Readarr API into native Librarry state, plus Readarr configuration resources such as delay/language/metadata profiles, metadata consumers, custom formats, restrictions, notifications, remote path mappings, download clients, and indexers into compatibility state.
- Native wanted metadata correction for title, author, cover URL, quality
profile, language, publisher, published date, series, series position, ISBN,
and monitoring state, with
manual_overridespersistence so provider refreshes do not overwrite corrected metadata. Wanted payloads include visible override state, Readarr-compatible book payloads project corrected bibliographic fields into their edition records, and individual override fields can be reset. - Wanted metadata provenance API and UI show the stored provider records behind a selected wanted item, including provider, matched fields, confidence, and the active manual overrides that protect corrected fields. Field-level evidence also marks canonical values, provider candidates, and conflicts that need manual review. A metadata review queue surfaces wanted items with unresolved provider conflicts before they become hidden library debt, while protected override fields stay visible on the selected wanted item. Supported provider candidates or all usable fields from one provider record can be applied as protected corrections without copying values by hand, and the current canonical value can be confirmed per field or in bulk across selected review items to clear reviewed conflicts without changing metadata.
- Postgres schema for authors, works, editions, series, provider records, manual overrides, files, wanted items, releases, and downloads.
- Scoped Downloads page for configured qBittorrent, Transmission, and SABnzbd clients: send approved book releases, add manual book downloads, inspect Librarry-tagged or all-client queues, perform Readarr-style queue actions, diagnose relevant file/tracker/category/tag issues, recover failed acquisitions, and import completed files without replacing the native download-client UI.
- Wanted-item persistence and release evaluation with approved/rejected decisions. Protected ISBN corrections are searched before broad title/author terms, exact ISBN hits can approve otherwise weak title matches, and protected language corrections are enforced during release scoring.
- Book-first acquisition queue summary for Readarr-style operations, including missing-search, ready-to-grab, queued/downloading, import-ready, imported, and blocked states with direct UI actions for search, grab, import, and recovery.
- Native Wanted queue filters for missing, wanted, grabbed, and all active items, with present-file suppression driven by tracked library files.
- Persisted quality profiles for ebooks and audiobooks, including minimum scores, upgrade cutoffs, seeder minimums, size limits, preferred terms, required terms, and rejected terms.
- Readarr-compatible release restrictions apply to native release evaluation as additional required, ignored, and preferred terms; tag-scoped restrictions apply to wanted items carrying matching tag IDs.
- Manual and scheduled wanted monitoring with monitor-run summaries and history events.
- Author subscriptions with all/future/none missing-book policies and manual or scheduled metadata refresh that creates or refreshes wanted items from monitored authors; skipped metadata candidates are persisted in an author metadata review queue with provider/title/date evidence and can be marked wanted or ignored from the monitor review UI. The Wanted page summarizes each monitored author's tracked, missing, grabbed, present, and metadata-review counts with a direct jump into that author's wanted books.
- Readarr-compatible author/book update and delete endpoints that persist monitor/unmonitor state, quality profile changes, and soft removals in Postgres.
- Manual and scheduled feed sync for Prowlarr-compatible indexer RSS feeds, with release persistence, matching against wanted items, optional paused auto-grab, and history events.
- Library scanning for configured ebook/audiobook roots or an ad hoc root path from the Imports UI, OPF sidecar, embedded EPUB, MP3 ID3, and M4B/MP4 metadata extraction, and manual file import into organized book folders.
- Completed-download import for Librarry-tagged download-client items, with
imported/error state persisted on download records. Downloads without a
wanted:<id>tag are auto-imported only when the import matcher finds one high-confidence ISBN match from provider records or protected overrides, or one title/author/format wanted item; ambiguous matches stay in the import review queue. - Calibre Content Server add-book handoff for manual or completed-download imports that target a Calibre-enabled Readarr-compatible root folder, plus basic set-fields metadata sync, configured output-format conversion starts with immediate and scheduled refreshable status snapshots, and delete-books handoff when deleting Calibre-backed files physically.
- Pending import review queue for ambiguous completed downloads that are not safely linked to a wanted item, with import/skip resolution, wanted-item suggestions, enforced per-review wanted-match selection before import, and explainable evidence from the UI.
- Readarr-compatible missing-book endpoints calculate missing state from wanted items plus tracked library files, so grabbed-but-unimported books remain visible while present files suppress false missing results.
- Readarr-compatible manual import endpoints for pending reviews, folder scans,
selected-file imports, and review-row resolution through
librarryReviewIdor a matching pending source path. - Readarr-compatible bookfile endpoints for imported library files: list/filter/get are mapped from native files, delete removes native file records with optional physical file removal, and update persists quality/language metadata plus Readarr IDs on the tracked file record.
- Native and Readarr-compatible file rename preview/apply flows using the active
library naming templates, including
/api/v1/renameandRenameFilescommand compatibility. - Readarr-compatible retag preview/apply flows, including
/api/v1/retagandRetagFilescommand compatibility, that persist desired title, author, language, and quality tag state on tracked file records. - Readarr-compatible calendar, history, and parse endpoints mapped from wanted items and Librarry history events.
- Configurable library naming templates for author folder, book folder, file
name, and optional space replacement through both Settings and
/api/v1/library/config. - Failed-download recovery for qBittorrent error/missing-file states and stale no-seed stalled downloads, with replacement search/grab and optional removal of failed torrents.
- Readarr-compatible blocklist and legacy blacklist endpoints populated from failed active downloads and failed Librarry history events, with single and bulk delete clearing download failure state and persisting compatibility tombstones for suppressed records.
- Readarr-compatible root folder list, lookup, create, update, and delete endpoints backed by Postgres, with environment-configured ebook/audiobook roots kept as defaults and Calibre Content Server fields round-tripped.
- Readarr-compatible filesystem, language, localization, log, update, and backup support endpoints for common Arr client probes.
- Readarr-compatible resource catalog endpoints for quality definitions, language profiles, metadata profiles, metadata consumers, tags, custom formats, restrictions, notifications, import lists, import-list exclusions, and remote path mappings, with create/update/list and delete persisted in Postgres.
- Readarr-compatible
ImportListSynccommand for enabled import lists with inline book entries, metadata lookup, deterministic fallback records, merged tags, and import-list exclusion checks. - Readarr-compatible Webhook notification delivery for grab, import, upgrade, failed-download, and test events using persisted notification resources.
- Readarr-compatible naming, media-management, host, UI, download-client, and indexer config endpoints with Postgres-backed compatible PUT/GET persistence, plus system-task endpoints derived from Librarry scheduler settings.
- Score-based upgrade search for grabbed/imported wanted items, with profile cutoffs, minimum score deltas, optional paused auto-grab, and history events.
- Metadata provider abstraction with initial adapters for Hardcover, Open Library, Google Books, and local OPF/embedded metadata; library import uses OPF and EPUB package metadata as high-confidence local evidence.
- Prowlarr-compatible release search for book indexers, exposed through both
native Librarry routes and stateful Readarr-compatible
/api/v1/releasesearch/grab that maps returned Arr release IDs back to persisted Librarry release decisions. - Native wanted release review reloads stored release decisions for the selected
wanted item, filters approved and rejected candidates, and allows an explicit
manual
forcegrab for a rejected candidate while scheduled automation still grabs approved candidates only. - qBittorrent integration for book categories, paused grabs, all-client and Librarry-tagged queue views, polling, simple active-queue rebalancing, single and bulk start, stop, delete, recheck, import, recovery, priority actions, per-torrent speed limits, manual URL/file adds, peer inspection, and tracker editing.
- Transmission integration for torrent add/list/start/stop/delete/recheck, torrent-file upload, location changes, labels, label-derived category/tag listing, label rename/delete, per-torrent speed limits, detail inspection, and file-priority controls.
- SABnzbd integration for NZB/Usenet grabs, queue/history polling, detail and queue-file inspection, plus start, stop, delete, rename, category, and priority actions, with category list/create/update/delete resource controls.
- Readarr-compatible API shim for common client probes and status views,
including optional
X-Api-Key/apikey/bearer authentication,/ping,/api/v1/system/status,/api/v1/health,/api/v1/system/backup,/api/v1/update,/api/v1/diskspace,/api/v1/filesystem,/api/v1/language,/api/v1/localization,/api/v1/log,/api/v1/rootfolder,/api/v1/queue,/api/v1/blocklist,/api/v1/blacklist,/api/v1/author,/api/v1/author/lookup,/api/v1/author/editor,/api/v1/book,/api/v1/book/lookup,/api/v1/book/editor,/api/v1/bookfile,/api/v1/calendar,/api/v1/history,/api/v1/rename,/api/v1/retag,/api/v1/parse,/api/v1/manualimport,/api/v1/wanted/missing,/api/v1/wanted/cutoff,/api/v1/qualityprofile,/api/v1/qualitydefinition,/api/v1/delayprofile,/api/v1/languageprofile,/api/v1/metadataprofile,/api/v1/metadata,/api/v1/customformat,/api/v1/tag,/api/v1/restriction,/api/v1/notification,/api/v1/importlist,/api/v1/importlistexclusion,/api/v1/remotepathmapping,/api/v1/downloadclient,/api/v1/indexer,/api/v1/release,/api/v1/command, and/api/v1/system/task, plus read-compatible host, UI, naming, media-management, indexer, and download-client config. Download-client, indexer, notification, and import-list compatibility resources include schema, test, action, and bulk mutation routes expected by common Arr clients. - Native Readarr compatibility report at
/api/v1/readarr/compatibilityand in the UI, separating ready, partial, and delegated areas so operators can see what behaves like Readarr and what remains owned by external download clients. - Docker Compose and TrueNAS custom-app deployment templates.
Metadata Strategy
Librarry does not depend on a single book database.
Provider priority:
- Hardcover is the preferred rich source for modern books, editions, series, ebook metadata, and audiobook metadata.
- Open Library is the open-data backbone for works, authors, editions, ISBNs,
and covers. Librarry treats Open Library author identity lookup separately
from author bibliography crawling: author lookup uses
/search/authors.json, while monitored authors with Open Library IDs use/authors/{id}/works.jsonbefore falling back to an author-name book search. - Google Books is an API-keyed exact-match fallback, not a primary graph.
- Local OPF, EPUB package metadata, MP3 ID3 tags, and M4B/MP4 metadata atoms are high-confidence import evidence.
- Manual overrides always win.
Goodreads, Amazon, and Audible scraping are intentionally not part of core.
Architecture
backend/ Go API, worker foundation, metadata adapters, acquisition clients
web/ Vite, React, TypeScript UI
deploy/ Dockerfiles, Compose files, TrueNAS template, sample environment
docs/ Architecture, metadata policy, local dev, provider setup
The backend owns provider credentials and normalization. The browser only talks to the Librarry API.
Important API surfaces:
- Readarr-compatible endpoints:
GET /pingHEAD /pingGET /api/v1/system/statusGET /api/v1/system/routesGET /api/v1/system/routes/duplicateGET /api/v1/healthGET /api/v1/system/backupGET /api/v1/updateGET /api/v1/diskspaceGET /api/v1/filesystemGET /api/v1/languageGET /api/v1/localizationGET /api/v1/localization/optionsGET /api/v1/logGET /api/v1/log/fileGET /api/v1/log/file/{filename}GET /api/v1/config/namingGET /api/v1/config/naming/{id}PUT /api/v1/config/naming/{id}GET /api/v1/config/naming/examplesGET /api/v1/config/mediamanagementGET /api/v1/config/mediamanagement/{id}PUT /api/v1/config/mediamanagement/{id}GET /api/v1/config/hostGET /api/v1/config/host/{id}PUT /api/v1/config/host/{id}GET /api/v1/config/uiGET /api/v1/config/ui/{id}PUT /api/v1/config/ui/{id}GET /api/v1/config/downloadclientGET /api/v1/config/downloadclient/{id}PUT /api/v1/config/downloadclient/{id}GET /api/v1/config/indexerGET /api/v1/config/indexer/{id}PUT /api/v1/config/indexer/{id}GET /api/v1/calendarGET /api/v1/historyGET /api/v1/history/sinceGET /api/v1/history/authorGET /api/v1/history/bookGET /api/v1/parseGET /api/v1/rootfolderGET /api/v1/rootfolder/{id}POST /api/v1/rootfolderPUT /api/v1/rootfolder/{id}DELETE /api/v1/rootfolder/{id}GET /api/v1/queueGET /api/v1/queue/detailsGET /api/v1/queue/statusPOST /api/v1/queue/grab/{id}POST /api/v1/queue/grab/bulkDELETE /api/v1/queue/{id}DELETE /api/v1/queue/bulkGET /api/v1/blocklistDELETE /api/v1/blocklist/{id}DELETE /api/v1/blocklist/bulkGET /api/v1/blacklistDELETE /api/v1/blacklist/{id}DELETE /api/v1/blacklist/bulkGET /api/v1/authorPOST /api/v1/authorGET /api/v1/author/lookupGET /api/v1/author/{id}PUT /api/v1/author/{id}DELETE /api/v1/author/{id}PUT /api/v1/author/editorDELETE /api/v1/author/editorGET /api/v1/bookPOST /api/v1/bookGET /api/v1/book/lookupGET /api/v1/book/{id}GET /api/v1/book/{id}/overviewPUT /api/v1/book/{id}PUT /api/v1/book/monitorDELETE /api/v1/book/{id}PUT /api/v1/book/editorDELETE /api/v1/book/editorGET /api/v1/bookfileGET /api/v1/bookfile/{id}PUT /api/v1/bookfile/{id}DELETE /api/v1/bookfile/{id}DELETE /api/v1/bookfile/bulkGET /api/v1/renameGET /api/v1/retagPOST /api/v1/retagGET /api/v1/wanted/missingGET /api/v1/wanted/missing/{id}GET /api/v1/wanted/cutoffGET /api/v1/wanted/cutoff/{id}GET /api/v1/qualityprofilePOST /api/v1/qualityprofileGET /api/v1/qualityprofile/{id}PUT /api/v1/qualityprofile/{id}DELETE /api/v1/qualityprofile/{id}GET /api/v1/delayprofilePOST /api/v1/delayprofileGET /api/v1/delayprofile/{id}PUT /api/v1/delayprofile/{id}DELETE /api/v1/delayprofile/{id}GET /api/v1/qualitydefinitionPUT /api/v1/qualitydefinition/{id}GET /api/v1/languageprofilePOST /api/v1/languageprofileGET /api/v1/languageprofile/{id}PUT /api/v1/languageprofile/{id}DELETE /api/v1/languageprofile/{id}GET /api/v1/metadataprofilePOST /api/v1/metadataprofileGET /api/v1/metadataprofile/{id}PUT /api/v1/metadataprofile/{id}DELETE /api/v1/metadataprofile/{id}GET /api/v1/metadataGET /api/v1/metadata/schemaPOST /api/v1/metadata/testPOST /api/v1/metadata/testallPOST /api/v1/metadata/action/{name}PUT /api/v1/metadata/bulkDELETE /api/v1/metadata/bulkPOST /api/v1/metadataGET /api/v1/metadata/{id}PUT /api/v1/metadata/{id}DELETE /api/v1/metadata/{id}GET /api/v1/customformatPOST /api/v1/customformatGET /api/v1/customformat/{id}PUT /api/v1/customformat/{id}DELETE /api/v1/customformat/{id}GET /api/v1/tagPOST /api/v1/tagGET /api/v1/tag/{id}PUT /api/v1/tag/{id}DELETE /api/v1/tag/{id}GET /api/v1/restrictionPOST /api/v1/restrictionGET /api/v1/restriction/{id}PUT /api/v1/restriction/{id}DELETE /api/v1/restriction/{id}GET /api/v1/notificationGET /api/v1/notification/schemaPOST /api/v1/notification/testPOST /api/v1/notification/testallPOST /api/v1/notification/action/{name}PUT /api/v1/notification/bulkDELETE /api/v1/notification/bulkPOST /api/v1/notificationGET /api/v1/notification/{id}PUT /api/v1/notification/{id}DELETE /api/v1/notification/{id}GET /api/v1/importlistGET /api/v1/importlist/schemaPOST /api/v1/importlist/testPOST /api/v1/importlist/testallPOST /api/v1/importlist/action/{name}PUT /api/v1/importlist/bulkDELETE /api/v1/importlist/bulkPOST /api/v1/importlistGET /api/v1/importlist/{id}PUT /api/v1/importlist/{id}DELETE /api/v1/importlist/{id}GET /api/v1/importlistexclusionPOST /api/v1/importlistexclusionGET /api/v1/importlistexclusion/{id}PUT /api/v1/importlistexclusion/{id}DELETE /api/v1/importlistexclusion/{id}GET /api/v1/remotepathmappingPOST /api/v1/remotepathmappingGET /api/v1/remotepathmapping/{id}PUT /api/v1/remotepathmapping/{id}DELETE /api/v1/remotepathmapping/{id}GET /api/v1/downloadclientGET /api/v1/downloadclient/schemaPOST /api/v1/downloadclient/testPOST /api/v1/downloadclient/testallPOST /api/v1/downloadclient/action/{name}PUT /api/v1/downloadclient/bulkDELETE /api/v1/downloadclient/bulkPOST /api/v1/downloadclientGET /api/v1/downloadclient/{id}PUT /api/v1/downloadclient/{id}DELETE /api/v1/downloadclient/{id}GET /api/v1/indexerGET /api/v1/indexer/schemaPOST /api/v1/indexer/testPOST /api/v1/indexer/testallPOST /api/v1/indexer/action/{name}PUT /api/v1/indexer/bulkDELETE /api/v1/indexer/bulkPOST /api/v1/indexerGET /api/v1/indexer/{id}PUT /api/v1/indexer/{id}DELETE /api/v1/indexer/{id}GET /api/v1/releasePOST /api/v1/releaseGET /api/v1/manualimportPOST /api/v1/manualimportGET /api/v1/commandPOST /api/v1/commandGET /api/v1/command/{id}DELETE /api/v1/command/{id}GET /api/v1/system/taskGET /api/v1/system/task/{id}
- Librarry-native endpoints:
GET /healthzGET /api/v1/providers/healthGET /api/v1/providers/diagnosticsGET /api/v1/readinessGET /api/v1/search?query=Project%20Hail%20MaryGET /api/v1/readarr/compatibilityPOST /api/v1/readarr/import/previewPOST /api/v1/readarr/importGET /api/v1/integrations/healthGET /api/v1/integrations/configPUT /api/v1/integrations/configPOST /api/v1/integrations/bootstrapPOST /api/v1/releases/searchPOST /api/v1/grabsGET /api/v1/downloadsGET /api/v1/downloads/{id}GET /api/v1/downloads/resourcesGET /api/v1/downloads/preferencesPUT /api/v1/downloads/preferencesPOST /api/v1/downloads/categories/actionsPOST /api/v1/downloads/tags/actionsPOST /api/v1/downloads/actionsPOST /api/v1/downloads/{id}/files/actionsPOST /api/v1/downloads/{id}/trackers/actionsPOST /api/v1/downloads/rebalancePOST /api/v1/downloads/recover-failedGET /api/v1/quality-profilesPOST /api/v1/quality-profilesGET /api/v1/authorsPOST /api/v1/authorsPATCH /api/v1/authors/{id}PUT /api/v1/authors/{id}DELETE /api/v1/authors/{id}POST /api/v1/authors/monitorGET /api/v1/authors/metadata/reviewPOST /api/v1/authors/metadata/review/{id}/resolveGET /api/v1/wantedPOST /api/v1/wantedPUT /api/v1/wanted/{id}PATCH /api/v1/wanted/{id}DELETE /api/v1/wanted/{id}GET /api/v1/wanted/metadata/reviewGET /api/v1/wanted/metadata/{id}POST /api/v1/wanted/metadata/{id}/applyPOST /api/v1/wanted/metadata/{id}/apply-bulkDELETE /api/v1/wanted/{id}/overrides/{field}POST /api/v1/wanted/{id}/searchGET /api/v1/wanted/releases/{id}POST /api/v1/wanted/{id}/grab(force: trueexplicitly overrides a rejected manual-search decision)POST /api/v1/wanted/monitorPOST /api/v1/wanted/feed-syncPOST /api/v1/wanted/upgradesGET /api/v1/librarry/historyGET /api/v1/library/configPUT /api/v1/library/configGET /api/v1/library/filesDELETE /api/v1/library/files/{id}POST /api/v1/library/files/deletePOST /api/v1/library/files/rename/previewPOST /api/v1/library/files/renamePOST /api/v1/library/calibre/conversions/refreshGET /api/v1/library/import-reviewsPOST /api/v1/library/import-reviews/resolve-bulkPOST /api/v1/library/scanPOST /api/v1/library/importPOST /api/v1/library/import-completedPOST /api/v1/library/import-reviews/{id}/resolvePOST /api/v1/settings/validate
Quick Start
Requirements:
- Go 1.23+
- Node.js 22+
- Docker and Docker Compose
- Postgres 16, unless using Compose
Run the full local stack:
git clone https://github.com/bandoracer/librarry.git
cd librarry/deploy
cp .env.example .env
docker compose up --build
Then open:
http://127.0.0.1:5173
Run the backend without Docker:
go test ./...
LIBRARRY_DATABASE_URL=postgres://librarry:[email protected]:5432/librarry?sslmode=disable \
go run ./backend/cmd/librarry
Run the web UI:
cd web
npm install
npm run dev
The Vite dev server proxies API requests to http://127.0.0.1:8080.
Configuration
Start from deploy/.env.example.
Common settings:
LIBRARRY_DATABASE_URL=postgres://librarry:librarry@postgres:5432/librarry?sslmode=disable
LIBRARRY_API_KEY=
LIBRARRY_HARDCOVER_TOKEN=
LIBRARRY_GOOGLE_BOOKS_API_KEY=
LIBRARRY_PROWLARR_URL=
LIBRARRY_PROWLARR_API_KEY=
LIBRARRY_QBITTORRENT_URL=
LIBRARRY_QBITTORRENT_USERNAME=
LIBRARRY_QBITTORRENT_PASSWORD=
LIBRARRY_TRANSMISSION_URL=
LIBRARRY_TRANSMISSION_USERNAME=
LIBRARRY_TRANSMISSION_PASSWORD=
LIBRARRY_SABNZBD_URL=
LIBRARRY_SABNZBD_API_KEY=
LIBRARRY_SABNZBD_USERNAME=
LIBRARRY_SABNZBD_PASSWORD=
LIBRARRY_EBOOK_CATEGORY=books-ebook
LIBRARRY_AUDIOBOOK_CATEGORY=books-audiobook
LIBRARRY_BOOK_TORRENT_ROOT=/data/torrents/books
LIBRARRY_EBOOK_LIBRARY_ROOT=/data/media/books/ebooks
LIBRARRY_AUDIOBOOK_LIBRARY_ROOT=/data/media/books/audiobooks
LIBRARRY_NAMING_AUTHOR_FOLDER={Author}
LIBRARRY_NAMING_BOOK_FOLDER={Title}
LIBRARRY_NAMING_FILE_NAME={Title}{Ext}
LIBRARRY_NAMING_SPACE_REPLACEMENT=
LIBRARRY_MONITOR_ENABLED=true
LIBRARRY_MONITOR_INTERVAL=30m
LIBRARRY_MONITOR_SEARCH_INTERVAL=6h
LIBRARRY_MONITOR_LIMIT=50
LIBRARRY_MONITOR_AUTO_GRAB=false
LIBRARRY_AUTHOR_MONITOR_ENABLED=true
LIBRARRY_AUTHOR_MONITOR_INTERVAL=6h
LIBRARRY_AUTHOR_MONITOR_SYNC_INTERVAL=24h
LIBRARRY_AUTHOR_MONITOR_LIMIT=50
LIBRARRY_FEED_SYNC_ENABLED=true
LIBRARRY_FEED_SYNC_INTERVAL=15m
LIBRARRY_FEED_SYNC_LIMIT=100
LIBRARRY_FEED_SYNC_AUTO_GRAB=false
LIBRARRY_FAILED_DOWNLOAD_ENABLED=true
LIBRARRY_FAILED_DOWNLOAD_INTERVAL=30m
LIBRARRY_FAILED_DOWNLOAD_STALLED_AGE=24h
LIBRARRY_FAILED_DOWNLOAD_LIMIT=50
LIBRARRY_FAILED_DOWNLOAD_AUTO_GRAB=false
LIBRARRY_FAILED_DOWNLOAD_REMOVE=false
LIBRARRY_FAILED_DOWNLOAD_DELETE_FILES=false
LIBRARRY_UPGRADE_SEARCH_ENABLED=true
LIBRARRY_UPGRADE_SEARCH_INTERVAL=12h
LIBRARRY_UPGRADE_SEARCH_LIMIT=50
LIBRARRY_UPGRADE_SEARCH_AUTO_GRAB=false
LIBRARRY_UPGRADE_SEARCH_MIN_DELTA=5
LIBRARRY_CALIBRE_REFRESH_ENABLED=true
LIBRARRY_CALIBRE_REFRESH_INTERVAL=15m
LIBRARRY_CALIBRE_REFRESH_LIMIT=200
LIBRARRY_CALIBRE_REFRESH_MAX_ATTEMPTS=1
LIBRARRY_API_KEY is optional for local development. When it is set, all
/api/ routes require a Readarr-compatible key through X-Api-Key, apikey,
apiKey, or Authorization: Bearer ...; /healthz and /ping stay open for
service probes. The web UI can store the key per browser from Settings.
Provider notes:
- Open Library works without credentials.
- Hardcover requires
LIBRARRY_HARDCOVER_TOKEN. - Google Books requires
LIBRARRY_GOOGLE_BOOKS_API_KEY. - Prowlarr requires URL plus API key.
- qBittorrent can use username/password or a trusted LAN setup with auth disabled for the calling host.
- Transmission can use username/password or a trusted LAN setup with auth disabled for the calling host.
- SABnzbd requires
LIBRARRY_SABNZBD_URLandLIBRARRY_SABNZBD_API_KEY. Username/password are optional and only needed when SABnzbd itself is behind basic auth. - Scheduled wanted monitoring is enabled by default. Set
LIBRARRY_MONITOR_AUTO_GRAB=trueonly when you want automation to send approved releases to the configured download client without a manual click. - Scheduled author monitoring is enabled by default. It only searches metadata and creates or refreshes wanted items; release grabbing still happens through wanted monitoring, feed sync, upgrades, recovery, or manual actions.
- Scheduled feed sync is enabled by default. Set
LIBRARRY_FEED_SYNC_AUTO_GRAB=trueonly when you want feed matches to send approved releases to the configured download client without a manual click. - Failed-download recovery is enabled by default in search-only mode. Set
LIBRARRY_FAILED_DOWNLOAD_AUTO_GRAB=trueto queue approved replacements andLIBRARRY_FAILED_DOWNLOAD_REMOVE=trueto remove failed torrents from qBittorrent after recovery.LIBRARRY_FAILED_DOWNLOAD_DELETE_FILES=truealso deletes the failed torrent payload when removal is enabled. - Upgrade search is enabled by default in search-only mode. Set
LIBRARRY_UPGRADE_SEARCH_AUTO_GRAB=trueonly when you want approved upgrades to be sent to the configured download client automatically. - Calibre conversion refresh is enabled by default when database persistence is available. It polls stored conversion jobs and updates completed/failed conversion metadata without starting new conversions.
- Naming templates support
{Author},{Title},{Format}, and{Ext}. Defaults keep the layout asAuthor/Title/Title.ext.
Deployment
The default Compose stack starts Postgres, the API, and the built web UI:
cd deploy
docker compose up --build
The TrueNAS custom-app template lives at
deploy/truenas/install.yaml. It intentionally
contains placeholder secrets and local image names. Build or publish your own
librarry-api and librarry-web images before installing it.
Development
Useful checks:
go test ./...
cd web && npm run build
git diff --check
The test suite currently covers provider normalization, matching confidence, settings validation, and API handlers. Fixtures and broader acquisition tests will grow as the automation path stabilizes.
Roadmap
- Author-level review controls beyond the current library-aware missing queue.
- Per-profile organization rules.
- Richer Calibre edition metadata sync, embedded metadata writes, path refresh after Calibre renames, and import rollback.
- Better edition selection for narrator, language, format, and ISBN.
- Hardcover and Google Books fixture coverage.
- Conflict-aware queue arbitration and additional download clients.
- Public image publishing and release builds.
Comments