When large language models are paired with a coding workflow, the cost of pulling source files into the model’s context quickly becomes a hidden bottleneck. A single cat or grep invocation can flood the prompt with thousands of tokens that carry little semantic weight—comments, unrelated functions, repeated import lines—yet they still count against the model’s limited window. For agents that iterate over a repository many times, this waste adds up, inflating both API‑usage bills and latency.
Projects that replace the naïve file‑read pipeline with a token‑aware layer can therefore shift the balance from “just get the text” to “get the right text.” That is the niche pluck tries to fill.
Enter pluck
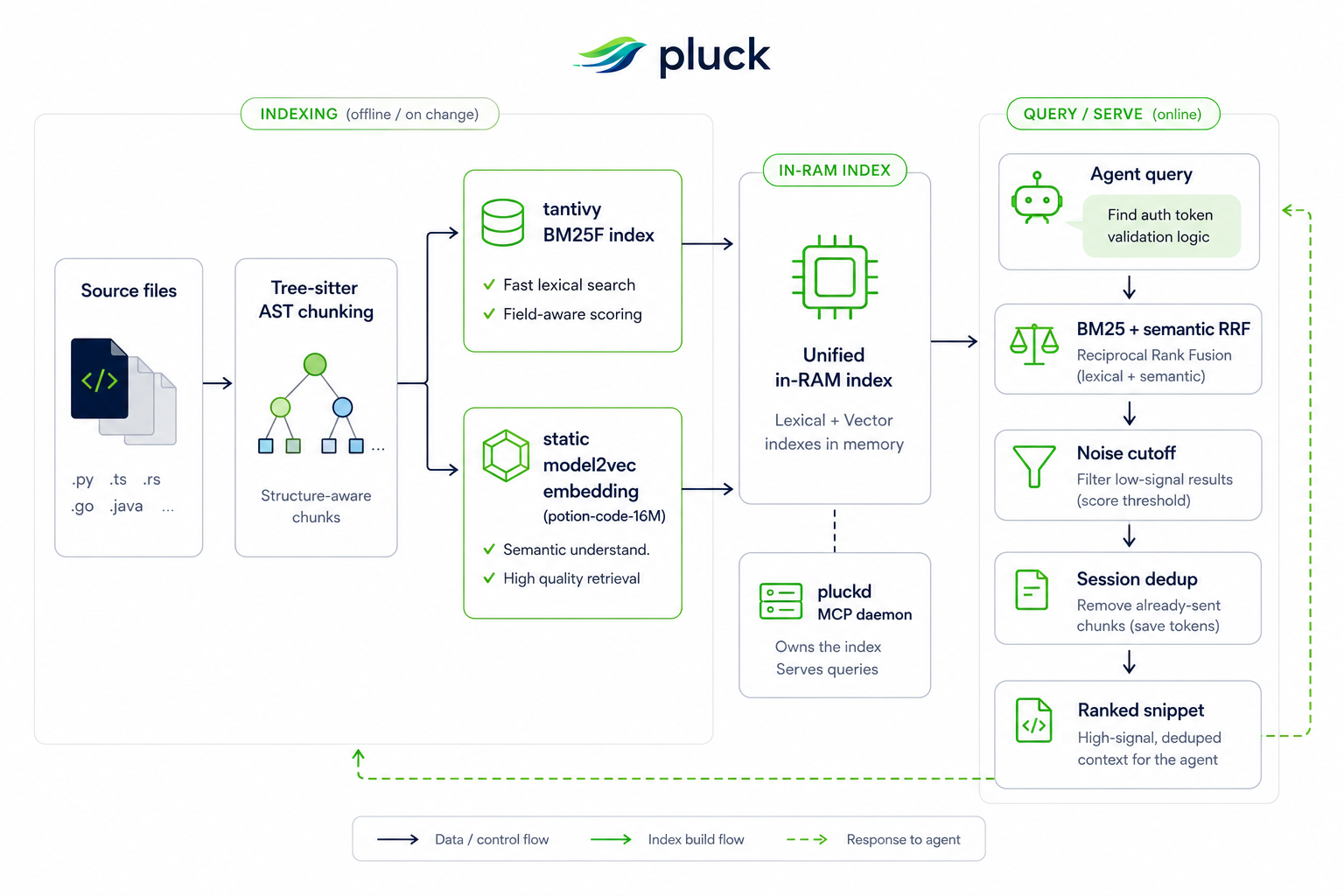
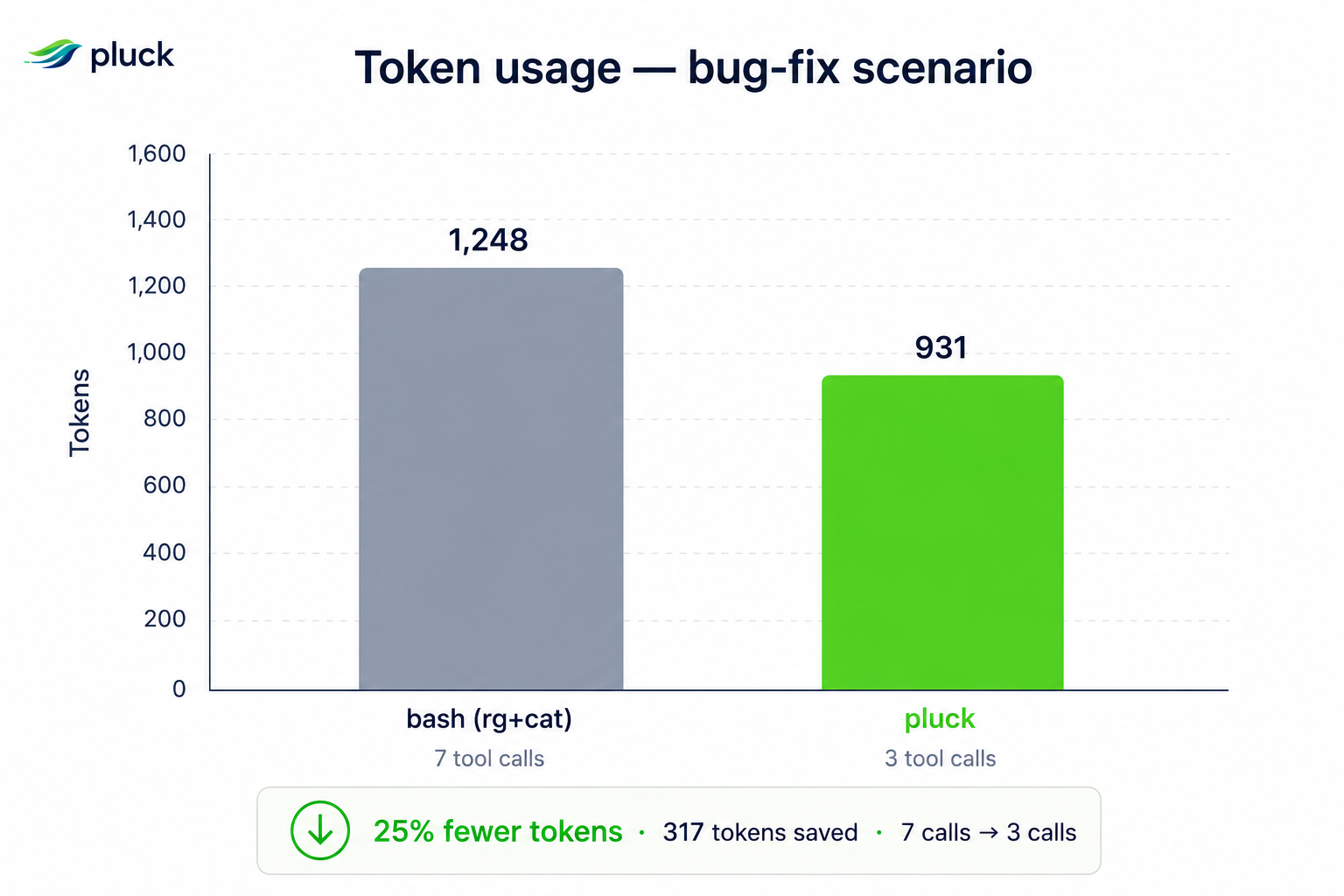
Pluck is a Rust‑based daemon that sits between an AI coding agent and the filesystem, exposing a suite of Model Context Protocol (MCP) tools that act as drop‑in replacements for classic Unix utilities. Instead of streaming an entire file, mcp__pluck__read produces a smart outline: a condensed map of signatures with tiny helper bodies inlined, while the full bodies can be fetched on demand. Search is handled by mcp__pluck__search, which blends BM25F keyword matching with a static code‑embedding model (potion-code-16M) to rank AST‑level chunks. The README claims 84–88 % fewer read tokens, 71 % shorter CI logs, and a warm‑search latency of 0.07 ms. All tools include a --raw fallback that behaves exactly like cat or grep, guaranteeing that the agent never loses capability if a request falls outside pluck’s knowledge.
The interesting bits
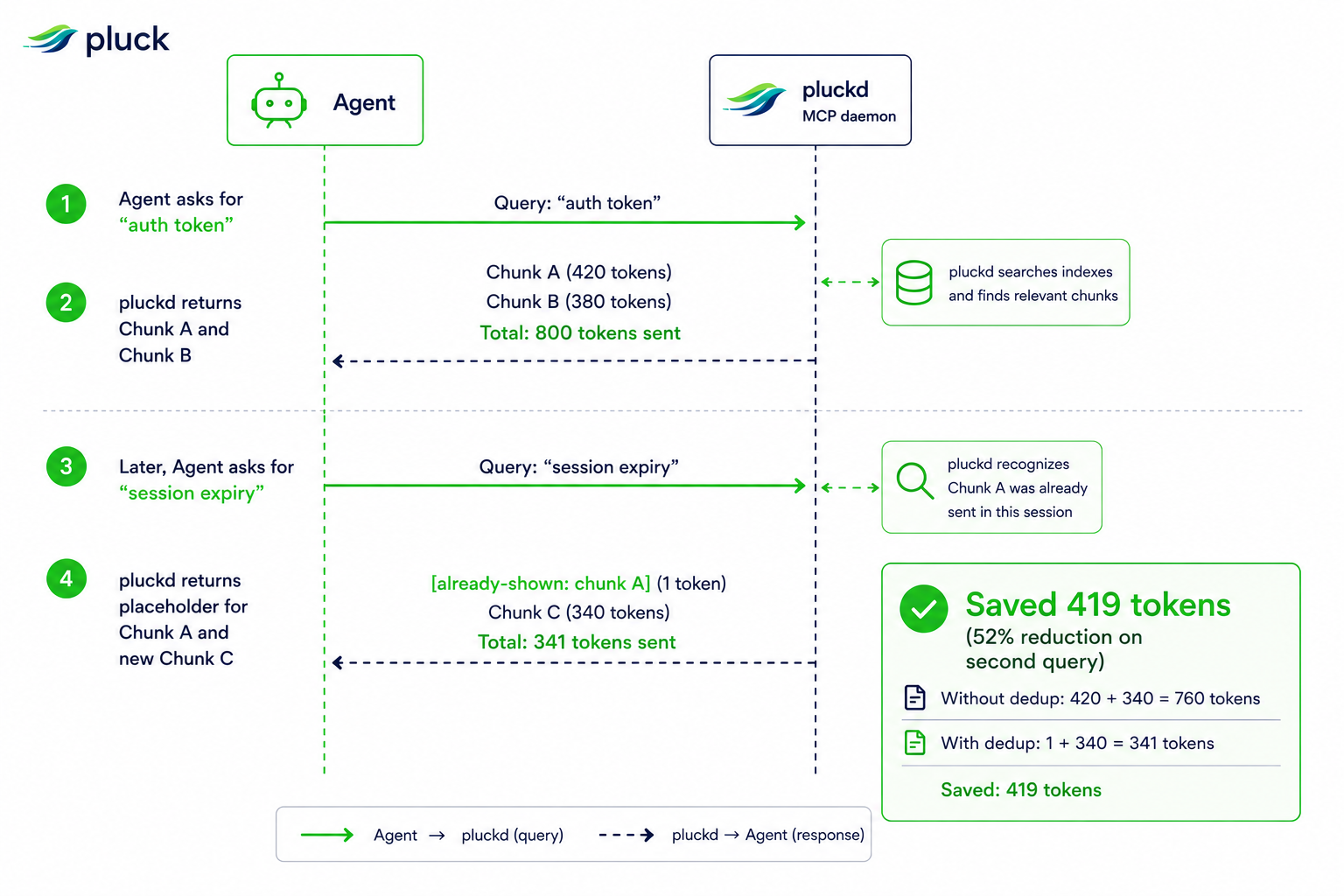
AST‑level chunking with Tree‑sitter – Pluck parses source files into syntactic fragments rather than plain lines. This granularity enables downstream tools such as mcp__pluck__symbol (read a single function or class) and mcp__pluck__impact (reverse call‑graph) to work on meaningful units. The approach also powers the session dedup mechanism: once a chunk has been sent to the model, later queries replace it with a one‑token placeholder, shaving roughly a quarter of tokens in a typical five‑query benchmark.
Hybrid retrieval pipeline – The search engine first expands a natural‑language query with nearest‑neighbor terms from the embedding index, then runs a two‑stage cascade: a BM25F pass to collect candidates, followed by an embedding‑based rerank using reciprocal rank fusion (RRF). This design lets agents locate code by concept (“payment flow”) without sacrificing precision on exact symbols. The embedding model lives on disk (~60 MB) and is consulted only for similarity scoring, avoiding runtime transformer inference.
MCP‑centric tool surface – Each capability is exposed as a named MCP tool (mcp__pluck__grep, mcp__pluck__deps, mcp__pluck__digest, etc.). The daemon runs persistently, so repeated calls avoid the cold start overhead of a traditional CLI. The tool set also includes higher‑level helpers: mcp__pluck__plan suggests the next 3–5 retrieval actions for a given task, and mcp__pluck__peek returns a function’s signature plus direct callees, useful for quick dependency checks.
Caveats
The project is still early‑stage: its benchmark table is based on a frozen baseline.json, and broader LLM‑in‑the‑loop measurements are earmarked for a future v0.8.0 release. Persistence is limited to an in‑memory index; a mmap‑backed on‑disk store is only road‑mapped for v0.7.0. Language coverage beyond TypeScript, Python and a handful of web‑centric formats is still in progress (Java, HTML, CSS, Markdown, etc. are in the v0.4.0 track, while C/C++ and JVM languages are slated for v0.5.0). Finally, the “lossless default” philosophy means that the default outline mode removes comments and types, which may be undesirable for agents that rely on documentation strings.
If you want to run it
Pluck requires a Rust 1.75+ toolchain (or a Homebrew tap) to install the pluck-mcp daemon and the optional pluck-cli. After installing, the daemon is registered as an MCP server for the target repository, and the appropriate mcp__pluck__* tools become the preferred retrieval methods. Detailed setup instructions, including agent‑specific init commands for Claude, Codex and Cursor, are in the project’s README.
Pluck offers a token‑efficient alternative to traditional file‑read loops, with a focus on AST‑aware indexing and hybrid semantic‑lexical search. Its design makes sense for teams that already run LLM‑backed coding assistants and want to curb prompt bloat without sacrificing raw access. The source is on GitHub.
Comments