If you work with data, you've probably been through this pain before. You have a Postgres or MongoDB database running in production, and someone on the analytics team needs that data in a data lake. So you start looking at tools — Debezium, Kafka Connect, Airbyte, Fivetran — and suddenly you're managing a whole Kafka cluster, writing custom configs, debugging connector issues, and wondering why a "simple" data pipeline turned into a full-time job.
OLake is trying to fix that. It's an open-source data ingestion engine built by the team at Datazip, and its whole thing is getting data from your databases into Apache Iceberg (or plain Parquet) as fast as possible, without all the infrastructure overhead.

What Does OLake Actually Do?
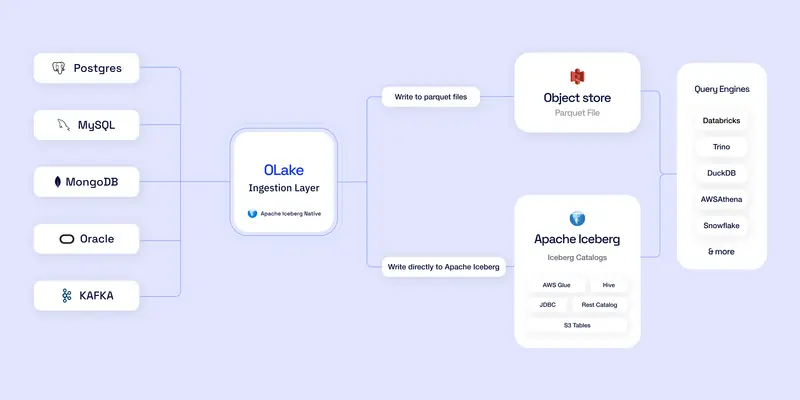
In simple terms: it replicates your database into a data lakehouse. You point it at your Postgres, MySQL, MongoDB, Oracle, or even Kafka — and it pulls the data out and writes it directly into Apache Iceberg tables or Parquet files sitting on S3, MinIO, GCS, or Azure.
No Kafka required. No Spark. No Flink. No Debezium. Just OLake talking directly to your source and writing to your destination.
It supports both full snapshots (dump everything) and CDC — Change Data Capture — so after the initial load, it keeps watching for changes and syncs them in near real-time using native database logs like pgoutput for Postgres, binlogs for MySQL, and oplogs for MongoDB.
The Numbers Are Kinda Wild
The benchmarks they published are hard to ignore. We're talking 580K records per second for Postgres full loads and 338K records per second for MySQL. They claim to be around 15x faster than Debezium and significantly cheaper than managed tools like Fivetran or Airbyte.
The whole thing is written in Golang, which helps explain the performance. Go's memory efficiency and concurrency model are a good fit for this kind of high-throughput data shuffling.
Supported Sources and Destinations
Here's what OLake can pull from right now:
- PostgreSQL — Full refresh, incremental sync, and pgoutput-based CDC
- MySQL — Full refresh, incremental sync, and binlog-based CDC
- MongoDB — Full refresh, incremental sync, and oplog-based CDC
- Oracle — Full refresh and incremental sync
- MSSQL — Full refresh and incremental sync
- DB2 — Full refresh and incremental sync
- Apache Kafka — Consumer group-based streaming
- S3 — Object store ingestion
And where it writes to:
- Apache Iceberg — with support for Glue, Hive, JDBC, and REST catalogs (Nessie, Polaris, Unity Catalog, AWS S3 Tables)
- S3 Parquet — plain Parquet files on MinIO, S3, or GCS
Once your data lands in Iceberg, you can query it with basically anything — Athena, Trino, Spark, Presto, Dremio, Databricks, Snowflake, ClickHouse, you name it.
How to Get Started
OLake ships with a web UI that runs via Docker Compose. Getting it up is genuinely a one-liner:
curl -sSL https://raw.githubusercontent.com/datazip-inc/olake-ui/master/docker-compose.yml | docker compose -f - up -d
That spins up the full stack — the UI, backend, Temporal for workflow orchestration, Postgres for internal state, and everything else.
Then just open http://localhost:8000 in your browser and log in with the default creds:
- Username: admin
- Password: password
From there it's pretty straightforward:
- Create a Job — go to the Jobs tab, click Create Job
- Configure your Source — point it at your Postgres, MySQL, MongoDB, whatever
- Configure your Destination — pick Iceberg or Parquet, set your catalog and storage
- Select your tables — choose which tables or collections to sync
- Hit sync — and watch it go
If you prefer the command line, there's also a full CLI with four main commands: spec, check, discover, and sync. The CLI is great for automation and plugging into orchestration tools like Airflow or Kubernetes.
Want to Kick the Tires First? Try the Playground
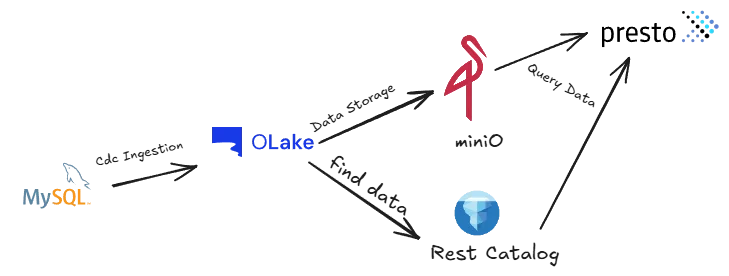
If you just want to see how everything fits together without connecting your own databases, OLake has a Playground. It's a self-contained Docker Compose environment that comes preconfigured with sample data, a source database, MinIO for storage, and Presto for querying.
One docker-compose up and you have a full lakehouse running on your laptop. Pretty neat for understanding the flow before committing to anything.
Why Not Just Use Airbyte or Fivetran?
Fair question. The short answer is speed and cost.
Airbyte and Fivetran are great products, but they come with trade-offs. Fivetran is managed but expensive. Airbyte is open-source but still relies on a connector framework that adds overhead, and for high-volume CDC workloads the performance gap becomes noticeable.
OLake was specifically built for the database-to-Iceberg use case. It doesn't try to be a universal connector platform for 300+ sources. It does a handful of things really well — and the "really well" part is the speed. The parallel chunking strategy, native BSON extraction for MongoDB, Arrow-based writes, and exactly-once delivery are all purpose-built for this specific workflow.
The other big thing is infrastructure simplicity. No Kafka cluster to manage. No Spark jobs to tune. The whole stack runs in Docker containers and the operational surface area is way smaller.
What's the Catch?
Like any young open-source project, there are rough edges. A few things to keep in mind:
- Delta Lake and Hudi destinations aren't supported yet (Iceberg and Parquet only for now)
- Oracle and MongoDB CDC are still maturing
- The project is moving fast, which means breaking changes can happen
- If you need 300+ connectors, this isn't the tool for that — it's laser-focused on databases to lakehouse
That said, the community is growing fast. The repo has 1.3k+ stars, an active Slack, and they run a contributor program and even participate in Google Summer of Code.
The Bigger Picture
The whole data lakehouse movement is about getting away from expensive, locked-in warehouses and moving to open formats that you control. Iceberg is winning that battle, and tools like OLake make the "getting data into Iceberg" part way less painful.
If you're a data engineer who's tired of managing Kafka + Debezium + Spark just to get database changes into your lake, OLake is worth a serious look. The setup is fast, the performance is legit, and the MIT-style Apache 2.0 license means you own your pipeline.
Links
- GitHub: https://github.com/datazip-inc/olake
- Docs: https://olake.io/docs
- Website: https://olake.io
- Slack Community: https://olake.io/slack
- OLake UI Repo: https://github.com/datazip-inc/olake-ui
Go try it. Worst case you lose 10 minutes on a docker compose up. Best case you replace half your data pipeline.
Comments