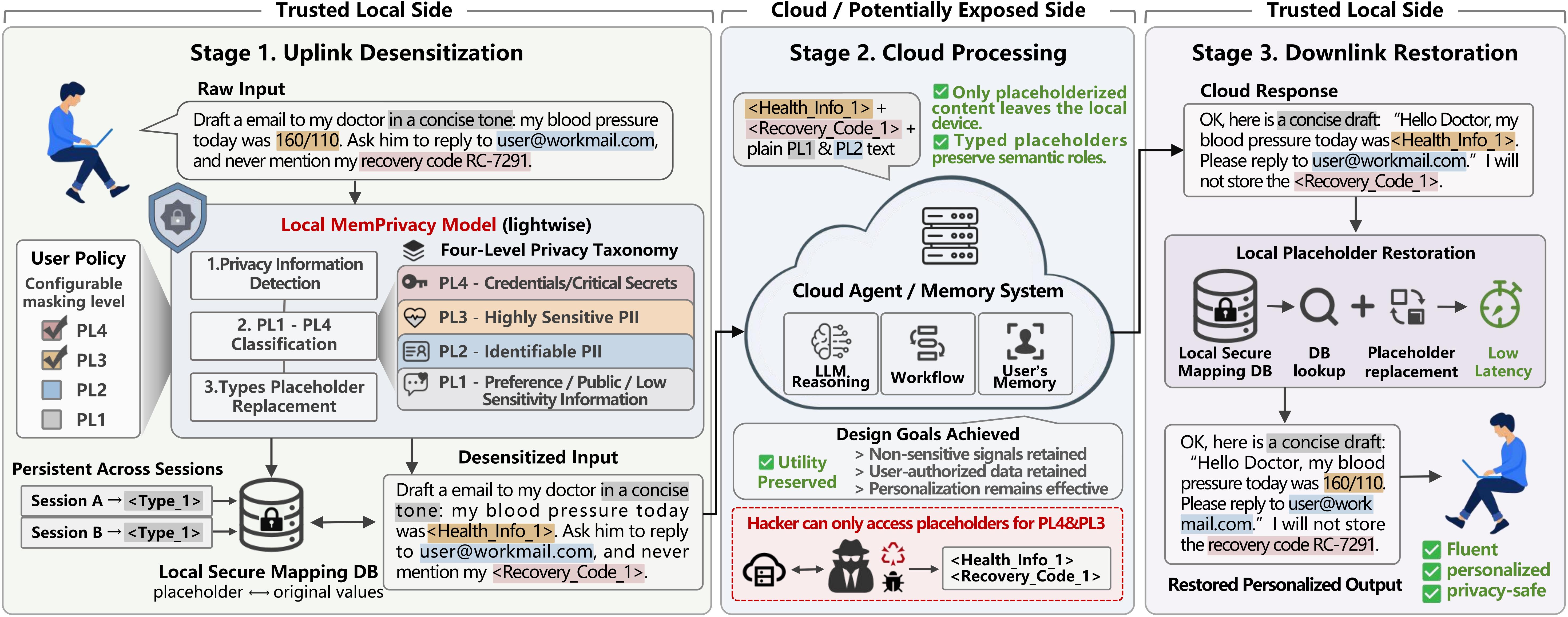
Edge-cloud agent architectures combine on-device processing with cloud resources to handle distributed tasks. Memory management in these systems—deciding what to store locally, what to sync, and how to keep data consistent—remains a core challenge. Many existing frameworks treat memory as a generic cache or state store, with limited attention to user privacy or the unique constraints of edge devices. MemPrivacy enters this space with a distinct focus: a privacy-preserving personalized memory management framework built for the edge-cloud split.
What MemPrivacy does differently
Most edge-cloud memory systems prioritize throughput or consistency without explicitly modeling privacy risk. MemPrivacy flips that priority. It is designed to manage agent memories—user interactions, context, and learned patterns—while keeping personal data private. The framework addresses two gaps at once: it adds privacy controls that let users or operators decide what data stays on the edge versus what reaches the cloud, and it supports personalization so that memory behavior adapts to individual agent profiles rather than applying a one-size-fits-all policy.
The project positions itself for developers building AI agents that run partly on edge hardware and partly in the cloud. Rather than treating memory as a single shared store, it enforces a boundary between local and remote memory with policies that can be tuned per user or per use case. This is particularly relevant when agents handle sensitive inputs—conversation history, sensor data, or personal preferences—where leaking raw data to the cloud is undesirable.
Quick start
The project is written in Python and can be installed from source. After cloning the repository, you can set up the package locally:
git clone https://github.com/MemTensor/MemPrivacy.git
cd MemPrivacy
pip install -e .
Once installed, the framework provides APIs for defining memory policies, registering edge and cloud backends, and attaching personalized memory handlers to agent loops. The README details configuration options and example integration patterns.
Trade-offs
Pros: The privacy-first design is the standout feature. For teams deploying agents where data sovereignty matters—healthcare, finance, or consumer-facing chat—having built-in controls over what leaves the edge device is valuable. Personalization support means memory behavior can differ across users without manual policy scripting. The Python base also makes it accessible for developers already working in that ecosystem.
Cons: The project is small—75 GitHub stars at the time of writing—and the community is limited. Documentation appears minimal; the README is the primary source of guidance. Python-only means it adds overhead if your stack is in another language. It's also likely heavier than simpler key-value caches if you only need basic state management without privacy layers.
Where it fits
If you're building edge-cloud agents and need to keep user data private while still allowing cloud-side reasoning, MemPrivacy targets that niche directly. It's not a general-purpose cache; it's a specialized framework for a specific architectural pattern. For larger deployments or teams with stricter compliance needs, the privacy controls may justify the added complexity. The source is on GitHub.
Comments