Library-First Engineering is a file-driven, persona-based framework designed for building production software with AI agents. Hosted on GitHub at StChiotis/Library-First-Engineering, it has garnered 24 stars. The project emphasizes language-agnostic, IDE-agnostic, and LLM-agnostic workflows, positioning itself as a process framework rather than a library, CLI tool, or config file. Its tagline—"Thinking in the Human · Processing in the AI · Truth in the Documentation"—captures the core idea: humans handle high-level thinking, AI processes tasks, and documentation serves as the single source of truth.
At its heart, the framework addresses common pitfalls in AI-assisted coding. These include logic hallucination, where models invent rules instead of following documented ones; context decay, where long sessions lead to inconsistent outputs; and spaghetti architecture, resulting from unchecked incremental edits. Library-First Engineering counters these through a Library of Truth—a set of interconnected prompts for LLM pipeline orchestration. These prompts, currently in Markdown format, function as an operating system for project personas. The file format is treated as secondary; the structure itself is authoritative, allowing adaptation to future token-efficient formats.
Core features
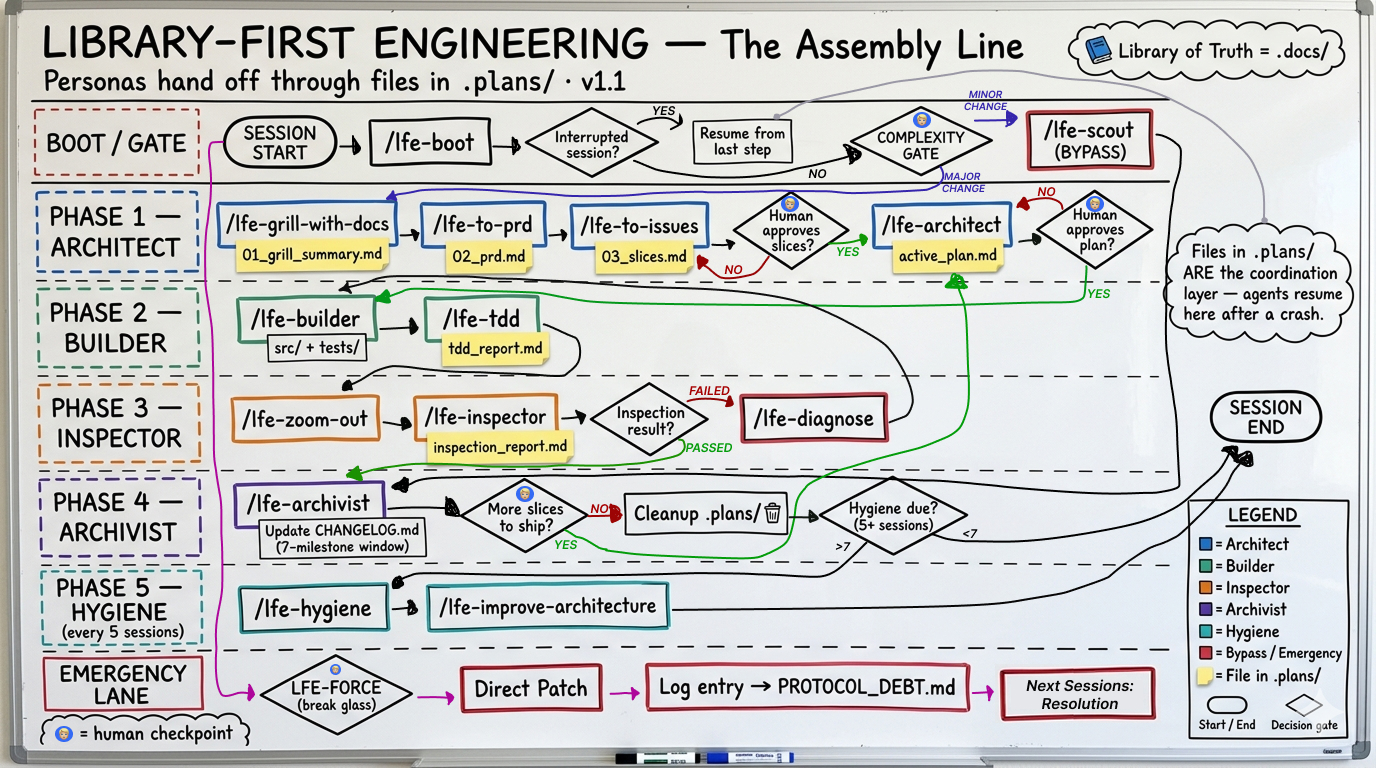
The framework structures collaboration via a file-based assembly line. Key elements include:
- Persona-based prompts: Specialized roles like Architect, Builder, Inspector, and Archivist handle distinct phases of development. Each persona loads only its contract, the active mission plan, and relevant library slices—avoiding full codebase or history dumps.
- Pipeline orchestration: Changes flow sequentially: Architect plans, Builder implements, Inspector reviews, Archivist documents. Users process one feature end-to-end per session.
- Complexity Gate: At session start, select Major Change (full pipeline) or Minor Fix (via
/lfe-scoutcommand). - Boot sequence: Run
/lfe-bootin an IDE or paste.agents/adapters/system_prompt.txtinto tools like ChatGPT or Claude.ai. - Library of Truth: Explicit, reusable prompts ensure reproducibility and prevent drift.
Status notes indicate it's stable and iterating, with active improvements limited to new persona behaviors and sub-pipeline skills in a backwards-compatible manner.
These features promote token efficiency by minimizing context per API call, reducing retries, and eliminating repeated project explanations. Over time, this flattens costs as projects scale.
Getting it running
Setup is straightforward and template-based, taking about 60 seconds for a quick start.
Click Use this template on the GitHub repo page, or run:
git clone https://github.com/StChiotis/Library-First-Engineering.git my-projectOpen the cloned directory in your IDE. At the start of every session, execute
/lfe-boot. Without an IDE adapter, copy the contents of.agents/adapters/system_prompt.txtas your first message in ChatGPT, Claude.ai, or any LLM chat before/lfe-boot.Respond to the Complexity Gate prompt: Choose Major Change for full pipeline runs or Minor Fix with
/lfe-scout.Execute one feature through the pipeline: Architect → Builder → Inspector → Archivist.
A detailed getting-started guide exists in the README, though the provided excerpt focuses on quick setup and philosophy. No additional dependencies like Docker, npm, or pip are mentioned—it's purely file-driven and prompt-based.
Who this is for
Library-First Engineering targets developers using AI agents for production software, particularly those facing scaling issues in AI-assisted workflows. It suits teams or solo builders iterating on long-term projects where consistency matters. Human contributors onboard by reading the library, bypassing chat log archaeology. AI agents benefit from explicit inputs, yielding reliable outputs.
Use cases include maintaining architectural discipline across sessions, lowering LLM API costs on growing codebases, and enforcing reproducible decisions. For instance, a developer adding features to a web app can boot the framework, gate complexity, and pipeline a single change without risking entropy. It's ideal for those tired of vanilla AI-coding's compounding context tax.
How it compares
Few direct alternatives exist, as Library-First Engineering is a process framework rather than a tool. It differs from chat-based AI coding (e.g., raw GitHub Copilot or Cursor sessions) by enforcing file-driven prompts over ad-hoc conversations. Compared to agent frameworks like Auto-GPT or LangChain pipelines, LFE prioritizes a minimal, persona-structured library without runtime dependencies—making it lighter but more manual.
Projects like Aider or OpenDevin offer AI pair-programming but lack LFE's emphasis on a persistent "Library of Truth" for multi-session reliability. LFE's token-saving approach stands out for cost-conscious users, though it requires discipline: one change per session limits rapid prototyping.
Benefits in practice
The framework's design yields measurable gains. Token efficiency comes from scoped contexts—personas avoid loading entire histories. This translates to lower API spend, as fewer tokens mean fewer retries and no re-briefing. Maintainability improves for new contributors, human or AI, who reference the library directly. Reliability stems from explicit prompts ensuring consistent architecture. Finally, it provides compounding leverage: initial library investment pays dividends, unlike workflows where context costs grow linearly.
In one line from the README: LFE keeps per-session costs—from tokens to attention—in check, preventing debt accumulation.
This approach isn't for everyone. Quick scripts or non-AI projects gain little from its structure. Hobbyists seeking speed over rigor might find the one-change-per-session rule restrictive. For production AI engineering, check the GitHub repo or its What is section.
Comments