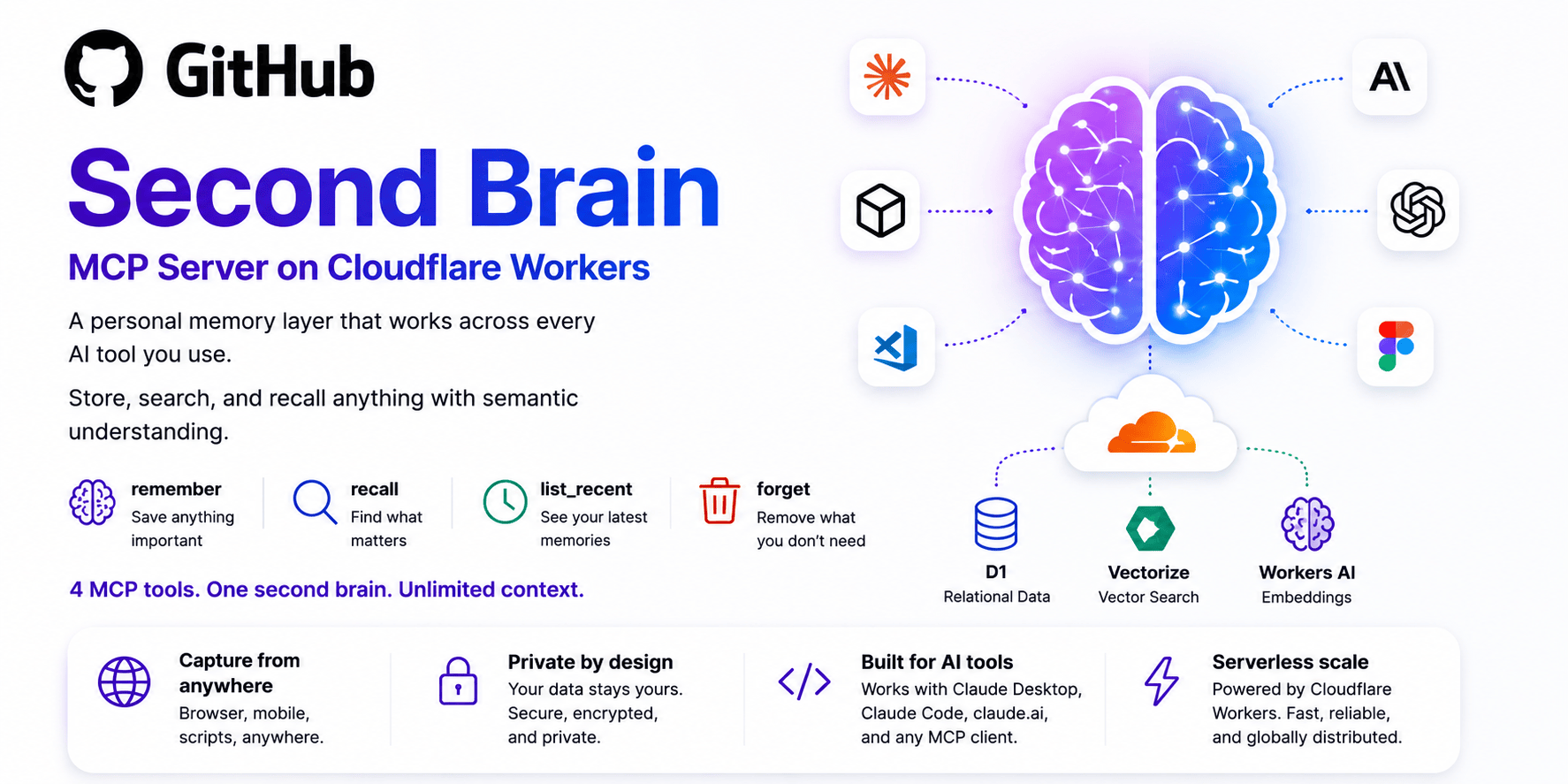
The challenge of sustaining contextual awareness in distributed AI environments remains a persistent hurdle. Many tools struggle to balance efficiency with reliability, leaving users reliant on external solutions. Second-brain-cloudflare emerges as a targeted response to this gap, offering a solution rooted in simplicity and scalability.
The Approach
The project employs a modular architecture designed to integrate seamlessly with existing AI infrastructures. By abstracting memory management from core applications, it prioritizes clarity and extensibility. Its core principle centers on embedding persistent storage within the interaction flow itself, minimizing latency and dependency on third-party services. This approach ensures compatibility across diverse platforms while maintaining strict adherence to open-source principles.
Trying it out
To initiate setup, navigating the repository provides straightforward pathways. A single line executes: docker build -t second-brain-cloudflare . For local execution, invoking second-brain-cloudflare start suffices. These commands reflect minimal barrier-to-adoption requirements, aligning with beginner-friendly workflows.
What it doesn't do
Despite its strengths, the solution lacks advanced optimization features. It cannot handle complex data types beyond basic strings or simple JSON structures. Additionally, its performance scales poorly under high concurrent usage, making it unsuitable for high-traffic environments. These limitations require careful consideration when selecting alternatives.
A pragmatic evaluation reveals that while second-brain-cloudflare simplifies data persistence, its constraints necessitate complementary tools. Whether it aligns with project goals remains a personal assessment. The source is on second-brain-cloudflare.
Comments