A vector database that gets out of the model's way. Multi-tenant, SSD-primary, RAM-frugal. Built for the machine where the LLM already owns most of the memory.
Hardware target. skeg was written and optimised for Apple Silicon (M-series). The numbers below are from an M1 Pro (16 GiB); the live dashboard is at
skegdb.github.io/bench. x86_64 native tuning (AVX2/AVX-512) lands as soon as we have server hardware to benchmark on; release binaries are aarch64 only (Apple Silicon, Linux ARM), the source builds on x86_64 but is not yet tuned for it.
The point
Most vector databases are designed to live alone on the machine. They expect every gigabyte of RAM the operating system can spare, and they take it.
skeg is built for the opposite case: a machine where the language model already owns most of the memory. The index sits on the SSD, a small bounded working set stays in RAM, and the rest of the system is left alone.
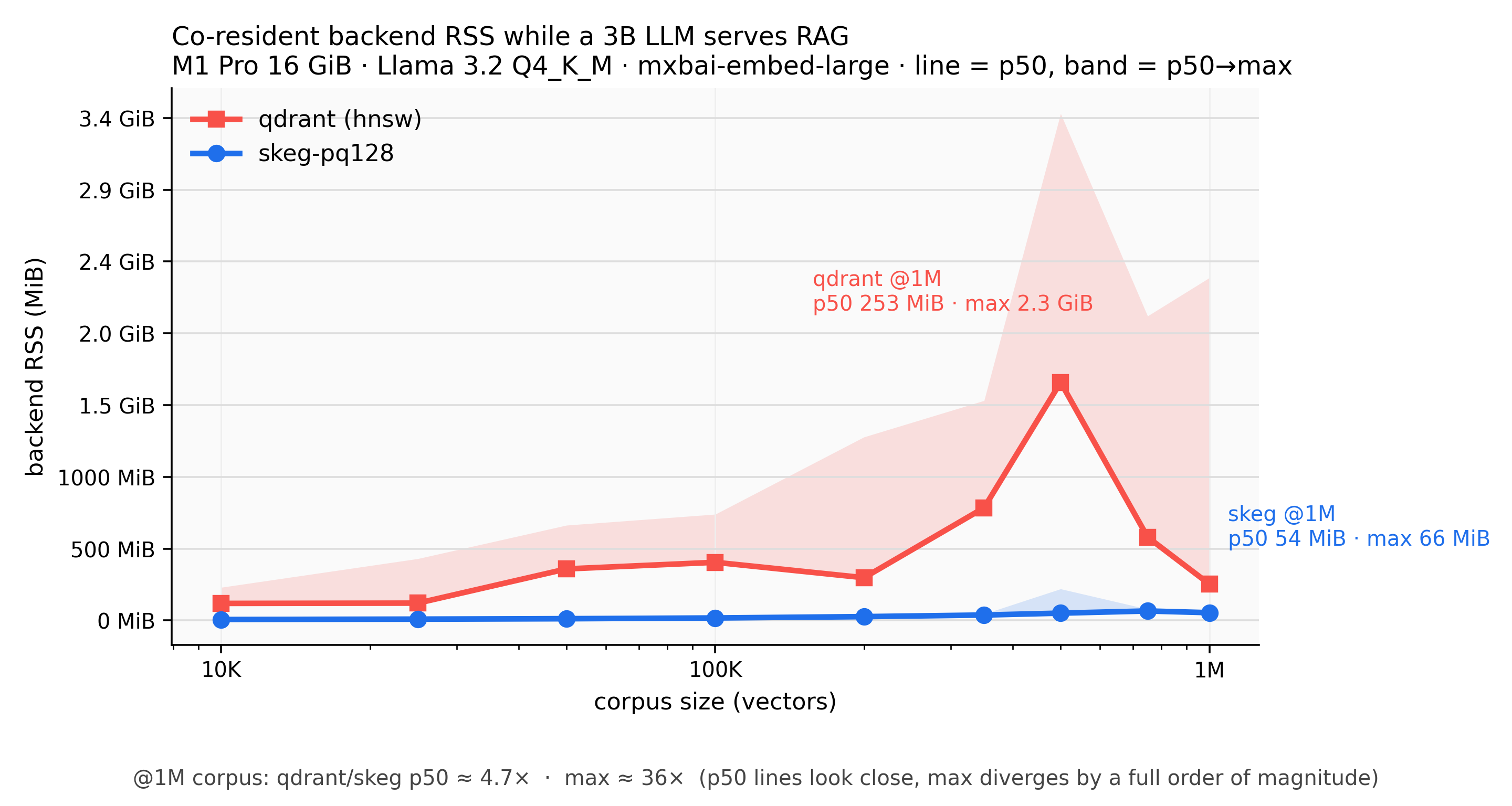
The number that matters is co-residence: a vector store serving retrievals while a local LLM is answering. A 3B model (Llama 3.2 Q4_K_M) running RAG over a corpus that sweeps from 10K to 1M vectors, both on the same M1 Pro.
| Co-resident with a 3B LLM, 1M vectors | backend RSS p50 | backend RSS max |
|---|---|---|
| skeg-pq128 | 54 MiB | 67 MiB |
| qdrant (hnsw) | 254 MiB | 2 387 MiB |
(Steady state vs. query bursts. The HNSW peak is where the swap pressure shows up; skeg stays flat because the working set is on SSD.)
The index lives on the SSD; when the query stream has gaps, the OS reclaims the cold pages and the resident set falls back toward nothing. The HNSW engines hold the graph and every vector in RAM the whole time. On a 16 GiB laptop where the model owns ~2.2 GiB and macOS takes several more, this is the difference between the machine breathing and the machine swapping.
The gigabytes you get back are the memory you can give to a larger model, a longer context window, a second model, a vision encoder, the application doing the actual work.
What it is
skeg is the storage layer for AI agents that run on the same hardware as the model. Vectors and key-value pairs in the same engine. Multi-tenant: prefix-routed namespaces with per-tenant isolation and a HELLO 3 AUTH authentication path (argon2id). Sized for machines that already have a language model resident in memory.
The server speaks two protocols. A native binary protocol on port 7379 for clients that want the lowest overhead. RESP3 on port 6379 for compatibility with existing Redis tooling. Both protocols expose the same operations.
What skeg is not
skeg is not the lowest-latency single-query engine; Qdrant is comparable on p99. A single shard saturates around 640 QPS, and past that you need multiple processes, not more cores. It is younger in production than Qdrant or Chroma. Where it wins is the regime it was built for: laptops, DGX Spark, edge boxes, anywhere RAM is contested.
For the full picture across engines, scales, and tiers, see the live dashboard: skegdb.github.io/bench. The isolated (non-co-resident) comparison at 500K is skeg-pq128 at ~228 MiB / recall@10 0.9994 against 2.3–3.0 GiB for the HNSW engines.
Install
Homebrew (macOS and Linux ARM)
brew tap skegdb/tap
brew install skeg
The formula installs both binaries (skeg, skeg-resp3) and a launchd/systemd service definition.
From crates.io
cargo install skeg-server
This compiles from source on the host machine and installs skeg and skeg-resp3 into $CARGO_HOME/bin. Requires a Rust toolchain (MSRV 1.88).
Other install methods (tarball, source, Docker) and the published crate list
Pre-built tarball
TARGET=aarch64-apple-darwin # or aarch64-unknown-linux-gnu
curl -L -o skeg.tar.gz \
"https://github.com/skegdb/skeg/releases/latest/download/skeg-$(curl -s https://api.github.com/repos/skegdb/skeg/releases/latest | grep tag_name | cut -d'"' -f4)-${TARGET}.tar.gz"
tar -xzf skeg.tar.gz
./skeg --help
SHA256 checksums are published alongside each tarball at the same URL with a .sha256 suffix. Pin a specific version from the releases page.
From source
git clone https://github.com/skegdb/skeg
cd skeg
cargo build --release --bin skeg --bin skeg-resp3
Requirements: Rust 1.88 or newer. The binaries are at target/release/skeg and target/release/skeg-resp3.
Docker
docker run -d --name skeg \
-p 7379:7379 \
-v skeg-data:/var/lib/skeg \
ghcr.io/skegdb/skeg:latest
The image bundles both skeg (native protocol, port 7379) and skeg-resp3 (Redis-compat, port 6379). The default entrypoint is skeg; for the RESP3 surface override with --entrypoint /usr/local/bin/skeg-resp3 and publish 6379 instead. Built for linux/arm64.
For an Ollama companion setup with docker compose, see docker-compose.example.yml.
Published library crates
skeg-proto, skeg-simd, skeg-platform, skeg-telemetry, skeg-resp3, skeg-core, skeg-vector, skeg-server, skeg-tenant, skeg-server-tenant, and skeg-multi-tenant. Network adapters live in the skeg-rigging and skeg-rigging-net repos.
Quickstart
Start the server. The native binary protocol listens on 7379; RESP3 listens on 6379.
skeg --data-dir ./data --addr 127.0.0.1:7379 &
skeg-resp3 --data-dir ./data --addr 127.0.0.1:6379 &
If you built from source, the binaries are at ./target/release/skeg and ./target/release/skeg-resp3.
Key-value through any Redis client:
$ redis-cli -3 -p 6379
> SET greeting "hello"
OK
> GET greeting
"hello"
> INCRBY counter 7
(integer) 7
Vector operations are namespaced under SKEG.* to stay out of the Redis command surface. Create an index, insert, search:
> SKEG.VINDEX.CREATE docs 1024 int8 flat
OK
> SKEG.VINDEX.LIST
name=docs dim=1024 kind=int8 backend=flat n_vectors=0
> SKEG.VSET docs 1 <1024-float vector as bytes>
OK
> SKEG.VSEARCH docs 10 100 <query vector bytes>
1) "1"
2) (double) 0.987
3) "7"
4) (double) 0.954
...
Command reference
SKEG.VINDEX.CREATE <name> <dim> <kind> <backend>. kind is the per-index storage precision: f32 | int8 | binary. backend chooses in-RAM flat scan or on-disk Vamana: flat | disk. The server-wide quantizer tier (int8, pq[:M:K], tq1, tq2, tq4) is selected via the --tier CLI flag at server start, not per-index. The vector payload in SKEG.VSET and SKEG.VSEARCH is a raw byte buffer on the native protocol, or a bulk string on RESP3.
Why it works
The architecture is the answer to a single constraint: the resident set of the index must hold while the model owns the rest of the memory.
The index lives on the SSD. The Vamana graph is walked on disk, with a small in-memory cache for the hot pages. Five tiers of vector quantization (int8, Product Quantization at 128×256, and TurboQuant at 1, 2, and 4 bits per coordinate) let you trade memory against precision. Re-ranking against full-precision vectors held on disk recovers the accuracy lost to quantization. The cache is S3-FIFO, bounded by a byte budget you configure, and gives evicted pages back to the operating system through jemalloc decay timers.
The substrate, the design decisions, and the eleven falsifications that produced this architecture are documented in the series on the project blog.
Status
Working today.
- KV operations on both protocols:
GET,SET,DEL,MGET,MSET,INCR,DECR,INCRBY,DECRBY,EXISTS,SELECT 0. - Vector operations on both protocols:
SKEG.VINDEX.CREATE,SKEG.VINDEX.DROP,SKEG.VINDEX.LIST,SKEG.VSET,SKEG.VDEL,SKEG.VSEARCH. - Admin / introspection:
SKEG.STATS,SKEG.SHARDS,SKEG.WHOAMI,HELLO 3 AUTH user pass(argon2id). - Multi-tenant: prefix routing and per-tenant isolation. Shipped in the
skeg-tenant,skeg-server-tenant, andskeg-multi-tenantcrates (Apache-2.0, same as the engine). - Three durability tiers: relaxed (
sync_data), kernel (fsync), and power-loss (F_FULLFSYNCon macOS). - Observability: Prometheus exporter on
--metrics-port(default-on) and OTLP/gRPC tracing viaSKEG_TRACE_OTLP_ENDPOINT(seeOBSERVABILITY.md). - Test suite covers the workspace with no clippy warnings under
cargo clippy --workspace --all-targets.
Not yet.
- Native Linux validation. Linux is tested only through Docker.
- The VSEARCH worker pool is opt-in via
--workers N; the inline default is what produced the benchmark numbers. - No GPU acceleration, no horizontal scaling across nodes, no hosted service.
- Native validation and architecture-specific tuning for x86_64 (Linux server hardware). Release binaries are aarch64 only; the SIMD path is NEON-only.
Documentation
The project blog at amanitaproject.com carries the long-form design and benchmark documentation:
- Constraints as Method. The operating envelope and the first five falsifications.
- Seven More Hypotheses, One That Survived. The path to TurboQuant.
- The Substrate. The vLog, the group commit, the Vamana index, and the memory budget.
- What Was Measured: The Numbers. The full benchmark record across engines, scales, and tiers.
Operational guides live in this repository:
OBSERVABILITY.md. Prometheus exporter, scrape config, OTel collector integration, tracing roadmap.
Live benchmark dashboard with the latest measurements (engine × scale × tier matrix, p50/p99 latency, recall, RSS): skegdb.github.io/bench.
Ecosystem
Federation (hansa) and ingest pipelines around the engine. See ECOSYSTEM.md.
Roadmap
Being explored, with no promised landing date. Direction depends on what shows up in real workloads and which constraint turns out to bite first.
- x86_64 native tuning (AVX2 / AVX-512 SIMD paths) for Linux server hardware.
- Child spans for the VSEARCH internals (walk, rerank) inside
skeg-vector, exposed through the OTLP exporter. - Native OTel metrics export, in addition to the current Prometheus path.
- GPU acceleration for the kernels, once the host environment makes it sensible.
Security
Security issues should be reported by opening an issue with a brief description and a request to move the conversation private. A dedicated mailbox will be activated shortly. See SECURITY.md.
Comments